2 MS SQL-
Server, Administration
2.1 Historie
|
1989
|
Version 1.0 für IBM OS/2
Entstand aus Zusammenarbeit von Microsoft mit der Fa. Sybase,
die Datenbankserver für Unix- Systeme entwickelte.
|
|
1992
|
Version 4.2 für OS/2 1.3
|
|
1993
|
Version 4.21 für Windows NT (SQLNT)
|
|
1995
|
SQL Server 6.0 für Windows NT (SQL95)
Eigenständige Weiterentwicklung der Datenbankservers ohne
Sybase
|
|
1996
|
SQL Server 6.5 für Windows NT (Hydra)
|
|
1999
|
SQL Server 7.0 für Windows NT (Sphinx, Plato)
Vollständige Neuentwicklung des Servers (Codebasis von
Sybase aufgegeben, eigene Codebasis entwickelt)
OLAP Tools
|
|
2000
|
SQL Server 2000 (Liberty)
|
|
2005
|
SQL Server 2005 (Yukon)
XML- Datentyp
CLR Integration
Filestream
|
|
2008
|
SQL Server 2008 (Katmai)
|
|
2010
|
SQL Azure (Matrix aka CloudDB)
|
|
2010
|
SQL Server 2008 R2 (Kilimanjaro)
|
|
2012
|
SQL Server 2012 (Denali)
|
|
2014
|
SQL Server 2014 (Hekaton)
|
2.2 SQL- Server 2014 Produktübersicht
|
|
|
|
|
Installierbar auf
|
|
|
Produkt
|
Max CPU's
|
RAM
|
Max DB Size
|
Windows 7
|
Windows Server
|
Anmerkung
|
|
Enterprise
|
OS - Grenze
|
OS - Grenze
|
524 PB
|
n
|
j
|
Umfasst alle Funktionen von SQLServer 2000. Vornehmlich zur
Implementierung großer Unternehmensdatenbanken.
|
|
Standard
|
4 Sockets oder 16 Kerne
|
128 GB
|
524 PB
|
n
|
j
|
Datenbankserver für Arbeitsgruppen. Spezielle Komponenten
der Enterprise Edition wie gutes Scalieren in SMP- Systemen,
Failover, Web- Schnittstelle und OLAP fehlen hier.
|
|
Web
|
4 Sockets oder 16 Kerne
|
64 GB
|
524 PB
|
n
|
j
|
Standalone Datenbankserver für Arbeitsstation.
Funktionsumfang = Standard Edition - Volltextsuche und
Transaktionsreplikation
|
|
Express mit advanced Services
|
1 Sockets oder 4 Kerne
|
1 GB
|
10 GB
|
j
|
n
|
Nur für Entwicklung und Test (spezielle Lizenz)
|
|
Express
|
1 Sockets oder 4 Kerne
|
1 GB
|
10 GB
|
j
|
n
|
Dient als Datenspeicher für Anwendungen. Keine
Benutzeroberfläche, Verwaltungstools, Mergerreplikation etc.
|
2.3 SQL- Server 2008 Produktübersicht
|
Produkt
|
CPU's
|
RAM
|
Max Size Database
|
Anmerkung
|
|
Enterprise- Edition
|
8
|
2 TB
|
no limit
|
Umfasst alle Funktionen von SQLServer 2000. Vornehmlich zur
Implementierung großer Unternehmensdatenbanken.
|
|
Standard- Edition
|
4
|
32GB
|
no limit
|
Datenbankserver für kleine und mittlere Unternehmen.
|
|
Web
|
4
|
32 GB
|
no limit
|
|
|
Express
|
1
|
1 GB
|
4 GB
|
Dient als Datenspeicher für Anwendungen.
|
2.4 Ältere Versionen und Abwärtskompatibilität
Datenbanken, die auf einer älteren Version von SQL-Server
erstellt wurden, können in sog. Kompatibilitätsmodus
auf
dem neuen System betrieben werden. Dabei werden Features, die nur im
neuen System verfügbar sind, abgeschaltet.
Der
Kompatibilitätsmodus einer DB wird mittels folgender
gespeicherter Prozedur abgefragt:
exec sp_dbcmptlevel '<db name>'
Die Prozedur gibt einen nummerischen Code zurück, der gemäß
folgender Tabelle zu interpretieren ist:
|
Code
|
SQL Server Version
|
|
60
|
6.0
|
|
65
|
6.5
|
|
70
|
7.0
|
|
80
|
SQL Server 2000
|
|
90
|
SQL Server 2005
|
|
100
|
SQL Server 2008 (+R2)
|
|
110
|
SQL Server 2012
|
|
120
|
SQL Server 2014
|
Der Kompatibilitätsmodus einer Datenbank kann auch festgelegt
werden. Dazu ist beim Aufruf von sp_dbcmptlevel der gewünschte
Versionscode als 2. Parameter anzufügen:
exec sp_dbcmptlevel '<db name>' <Code>
2.5 Dokumentation
Zum SQL- Server kann im Internet unter folgender URL eine aktuelle
Dokumentation abgerufen werden:
http://msdn.microsoft.com/de-de/library/bb545450.aspx
2.6 Datenbankarchitektur
2.6.1 Allgemeiner Aufbau eines Datenbankservers
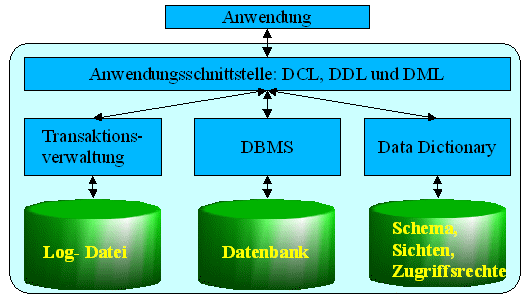
2.6.2 Betriebsarten
|
Definition
|
|
OLTP
|
(engl.: Online Transaction Processing) In dieser Betriebsart
wird eine Datenbank zur Verwaltung der Daten in laufenden
Geschäftsprozessen (Verwaltung von Bankkonten,
Buchungssysteme etc.) benutzt.
|
|
Definition
|
|
OLAP
|
(engl.: Online Analytical and Processing) In dieser
Betriebsart werden große Datenmenge komplexen Analysen
unterworfen. Grundlegende Datenstruktur dafür sind sog.
Cubes (vergleichbar mit Excel- Tabellenblättern, die
sich in n- Dimansionen aufspannen). Durch spezielle Abfragen
untersützt SQL- Server das Cube- orientierte
Auswertungsschema.
|
2.6.3 Übersicht SQL Server ab 2005
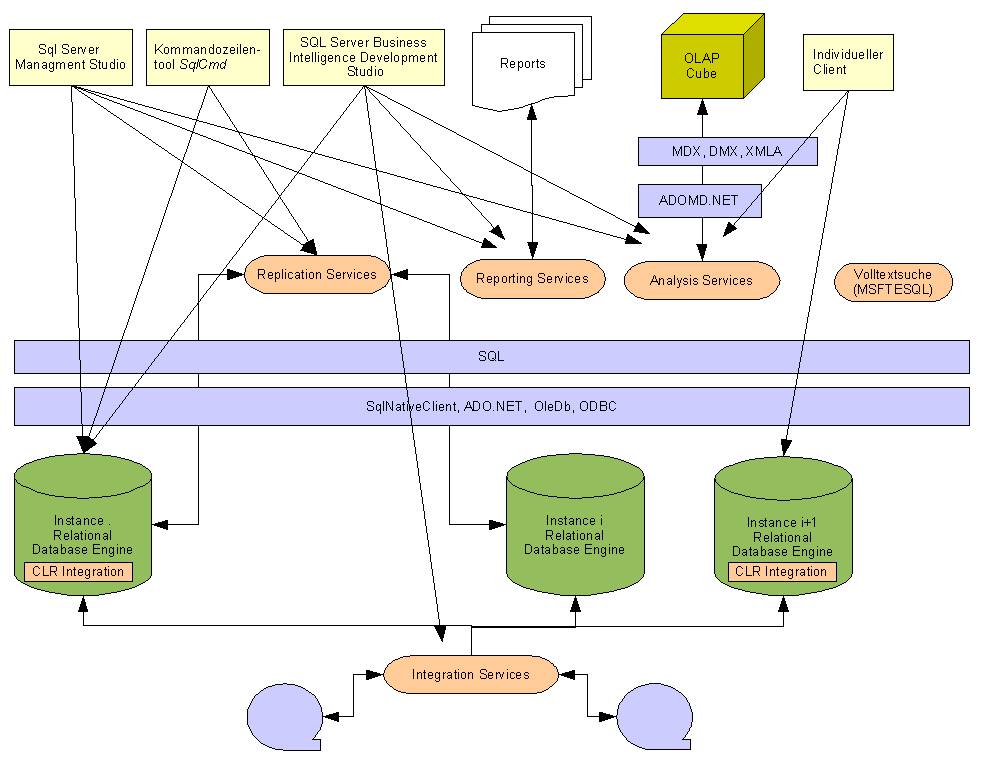
2.6.4 Server- Komponenten
|
SQL Server
|
Microsoft Search
|
SQL Server Agent
|
Distributet Transaction Coordinator
|
|
Dieser Dienst implementiert das relationale Datenbankmodul.
|
Dieser Dienst implementiert für alle Instanzen von SQL-
Server auf einem Serversystem die Volltextsuche.
|
Ausführen von SQL Server-
Tasks zu bestimmten Uhrzeiten
Prüfen, ob aktueller
Zustand des Servers bestimmte Bedingungen erfüllt. Wenn ja,
dann können vom Administrator eingestellt Aktionen
ausgeführt werden (z.B: Benachrichtigung per email).
Ausführen von Replikationstasks, die der
Administrator zuvor definiert hatte
|
Dieser Dienst ist für die Verwaltung verteilter
Transaktionen verantwortlich.
|
2.6.5 Applikationsschnittstellen
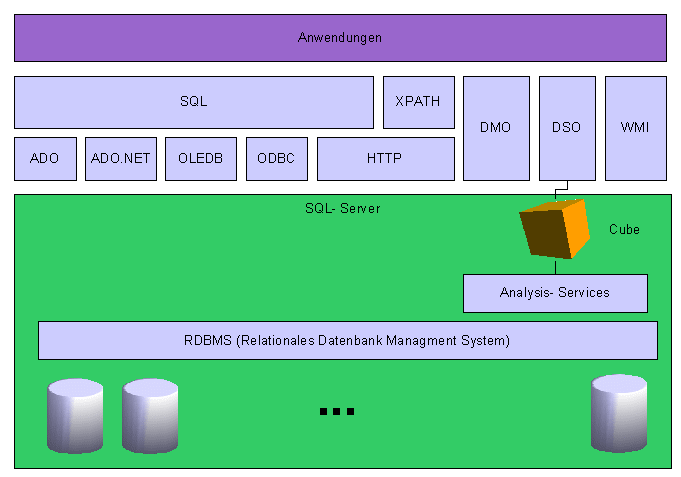
2.6.5.1 DMO
DMO (engl.: Distributet Managment Objects) ist eine COM- basierte
API, die alle administrativen Funktionen zur Manipulation beliebiger
Entites auf der Datenbank bereitstellt.
2.6.5.2 DSO
DSO (engl.: Decision Support Objects) ist eine COM- basierte
Schnittstelle, welche alle administrativen Funktionen zu den
SQLServer 2000 Analysis- Diensten bereitstellt. Damit sind OLAP-
Applikationen programmierbar.
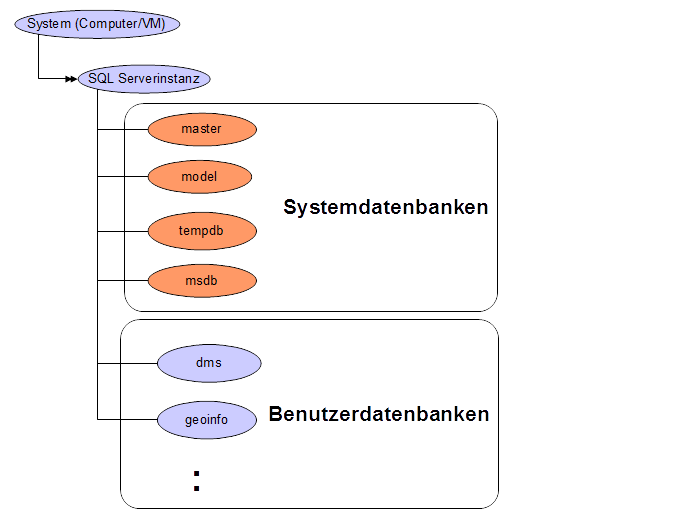
2.6.6 Serverinstanzen und Datenbanken
Wurde das SQL- Server Softwarepaket auf einem System (= physischer
Computer oder VM) installiert, dann können beliebig viele
Serverinstanzen eingerichtet
werden. Eine Serverinstanz ist ein Host für wiederum beliebig
viele Datenbanken (System/Benutzer). Folgendes Bild veranschaulicht
die Zusammenhänge:
2.6.6.1 UNC
Namen für Serverinstanzen
Die einzelnen Serverinstanzen können über
Datenbankclients wie das Microsoft Managment Studio
angesteuert werden, indem eine
Datenbankverbindung aufgebaut wird. Die Datenbankverbindungen werden
über sogenannte Verbindungszeichenfolgen (engl.:
ConnectionString) konfiguriert wie folgende:
Provider=SQLOLEDB.1;Integrated Security=SSPI;Persist Security Info=False;Initial Catalog=KeplerDB;Data Source=Werk12\SQL2012dev
In einer solchen
Verbindungszeichenfolge wird der Datenbankserver durch einen Namen,
welcher der Universal Naming Convention (kurz:
UNC) folgt, definiert. Im Beispiel hier:
Data Source=Werk12\SQL2012dev
Ein UNC Name für eine SQL- Serverinstanz besteht dabei aus zwei
Teilen:
<Systemname>\<Instanzname>
Beim Zugriff über Domänengrenzen hinweg ist zusätzlich
der Domäne- Name anzugeben:
\\<domain-name>\<Systemname>\<Instanzname>
Der Systemname entspricht dabei dem Name des Host- Systems (cmd>
hostname) in der Arbeitsgruppe oder Domäne.
Soll die Verbindung über einen
ausgewählten TCP- Endpunkt erfolgen, dann kann im UNC- Name auf
das TCP- Protokoll mittels des Präfixes tcp:
eingeschränkt werden. Die Portnummer wird mittels Komma an den
Systemname angehangen:
tcp:<Systemname>,<Portnummer>\<Instanzname>
z.B. tcp:Werk12,12345\SQL2012dev
Wurde mit dem SQL- Server Installationsprogramm eine Standardinstanz
eingerichtet, dann ist sie unbenannt. Sie wird mit einem UNC- Namen
== Systemnamen adressiert. Für das System Werk12 z.B. einfach
Werk12
Wird mit einem Client auf die Standardinstanz zugegriffen, der auf
dem gleichen System läuft wie der Server, dann kann der
Systemnamen durch den Punkt ersetzt werden
.
Soll auf einem System neben der
Standardinstanz weitere eingerichtet werden, dann sind sie bei der
Installation zu benennen. Die vergebenen Namen dienen dann beim
Adressieren in der Verbindungszeichenfolge zur Identifizierung der
Serverinstanz. Wurde z.B. auf dem System Werk12 eine
Instanz mit dem Name SQL2012dev eingerichtet,
dann lautet der UNC:
Werk12\SQL2012dev
Wird der Client auf dem gleichen System gestartet, auf dem auch die
Serverinstanz läuft, dann kann der UNC vereinfacht werden zu
.\SQL2012dev
Die Verbindungszeichenfolge zu einem Server kann man wie folgt
ermitteln:
neue Textdokument auf dem Desktop
anlegen (Endung .txt)
Endung von Textdokument umbenennen
in .udl
Doppleklick auf udl- Dokument.
Über den sich öffnenden Assistenten den UNC- Name für
den Server und die Datenbank auswählen.
Assistenten schließen
Endung der udl- Datei in .txt
zurückbenennen
txt- Datei mit Texteditor öffnen
und Verbindungszeichenfolge ablesen
2.6.6.2 Systemdatenbanken
Jede SQL Server Instanz besitzt 4 Systemdatenbanken, in denen
Konfigurationsdaten gespeichert werden:
|
Datenbankname
|
Inhalt
|
|
master
|
Daten für Serverinitialisierung, Serverkonfiguration,
Liste aller Datenbanken, Anmeldekonten, Pfade der primären
Dateien von Datenbanken
|
|
tempdb
|
temporäre Tabellen und gespeicherte Prozeduren
|
|
model
|
Vorlage für alle Benutzerdatenbanken. Wird eine
Benutzerdatenbank erstellt, dann werden alle Tabellen aus model
in neue Benutzerdatenbank kopiert.
|
|
msdb
|
Tabellen für SQL Server Agent
|
2.6.6.3 Allgemeine Struktur einer SQLServer Datenbank
Eine
Datenbank ist einer Serverinstanz untergeordnet und besteht aus
Datenbankobjekten wie Tabellen (Primärspeicher), Views
(sekundäre Darstellung der Datenbankinhalte) etc..
2.6.7 Data- Dictionary: System- und Datenbankkatalog
2.6.7.1 Der Systemkatalog
Der Systemkatalog ist durch die Datenbank master
realisiert, und besteht aus Tabellen, die alle Daten zur Verwaltung
einer SQL- Serverinstanz enthalten.
|
Systemtabelle
|
Inhalt
|
|
Sysaltfiles
|
Zu jeder Datei ist ein Datensatz enthalten mit : Datei-ID,
Datenbank-ID, Dateiname, Speicherort, Größe und
Vergrößerungseigenschaften
|
|
Sysdatabases
|
Zu jeder Datenbank is ein Datensatz enthalten mit: DBID, SID
des Besitzers, Erstellungsdatum, Speicherort der primären
Datei.
|
|
Sysdevices
|
Zu jedem Sicherungsgerät gibt es einen Datensatz
|
|
Syslockinfo
|
Zu jeder aktiven Sperre wird ist ein Datensatz enthalten mit:
ID des gesperrten Objektes, user- od. Prozessid, der Sperre
anfordert
|
|
Sysxlogins
|
Datensatz zu jedem Anmeldekonto
|
|
Sysmessages
|
Liste aller möglichen Fehlermeldungen
|
2.6.7.2 Der Datenkatalog
Der Datenkatalog enthält die Definition aller Objekte einer
Datenbank wie Tabellen, Indizes und Benutzer. Er wird durch einen
Satz von Tabellen in jeder Datenbank realisiert. Datenkatalog und
Datentabellen bilden eine Einheit, die auf eine Serverinstanz kopiert
die Datenbank realisiert.
|
Systemtabelle
|
Inhalt
|
|
Syscomments
|
Datensatz zu jeder Sicht, Regel, Trigger, CHECK-
Einschränkung, gespeicherten Prozedur usw. Textspalte
enthält ursprüngliche TSQL- Anweisung zur erstellung
des Objektes. Einträge dürfen weder geändert noch
gelöscht werden.
|
|
Sysindexes
|
Datensatz zu jedem Index in der DB
|
|
Sysobjects
|
Datensatz zu jedem Objekt in der DB mit: Objekt ID, Benutzer
ID, Erstellungsdatum
|
|
Sysusers
|
Datensatz zu jedem Benutzer der Datenbank
|
2.7 Verwaltungswerkzeuge / Datenbankclients
Im Folgenden eine Aufstellung der wichtigsten Verwaltungswerkzeuge
ab Sql-Server 2005. Verwaltungswerkzeuge älterer Versionen
werden hier nicht berücksichtigt.
2.7.1 SQL Server Managment Studio
GUI-
Tool für
Administration von Serverinstanzen
Erstellen und Ausführen von TSQL- Skripte
Verwalten von Integration Service- Paketen (über
Integration Service Kataloge)
Verwalten von Berichten
2.7.2 Kommandozeilentool SqlCmd.exe
Befehlszeilenshell zur Ausführung von Transact- SQL
Anweisungen. Zur Kommunikation mit dem Server wird die OLE DB-
Schnittstelle verwendet.
Verbinden mit der 1. Serverinstanz über ein Windows-
Benutzerkonto
sqlcmd -E
Verbinden mit der 1. Serverinstanz über ein SQL- Konto
(Benutzername, Passwort)
sqlcmd -U mko -P XXXXX
Verbinden mit der Instanz SQLEXPRESS auf dem Server Shuttle
sqlcmd -E -S Shuttle\SQLEXPRESS
Ausführen des Scripts createDB.sql mittels osql beim
Start
sqlcmd -E -i createDB.sql
Direktes Ausführen einer Abfrage auf dem lokalen SQLEXPRESS-
Server
sqlcmd -E -S .\SQLEXPRESS -q "SELECT * from dbo.files where SizeInBytes < 1024*1024"
2.7.3 SQL Server Oberflächenkonfiguration
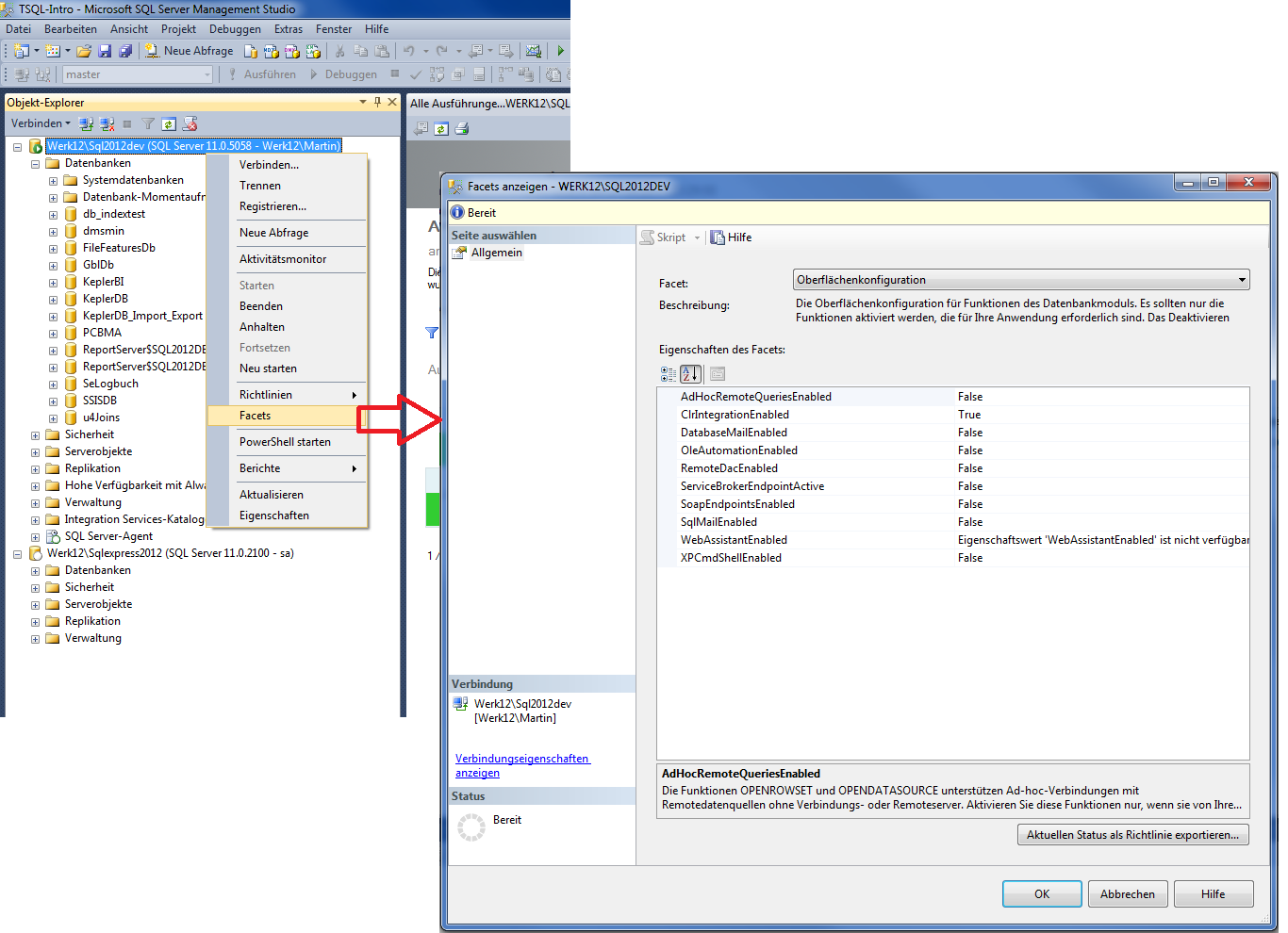
Wird aus dem SQL Server Managment
Studio gestartet. Funktionen des Datenbankmoduls werden hier
eingestellt.
2.7.4 SQL Server Konfiguration
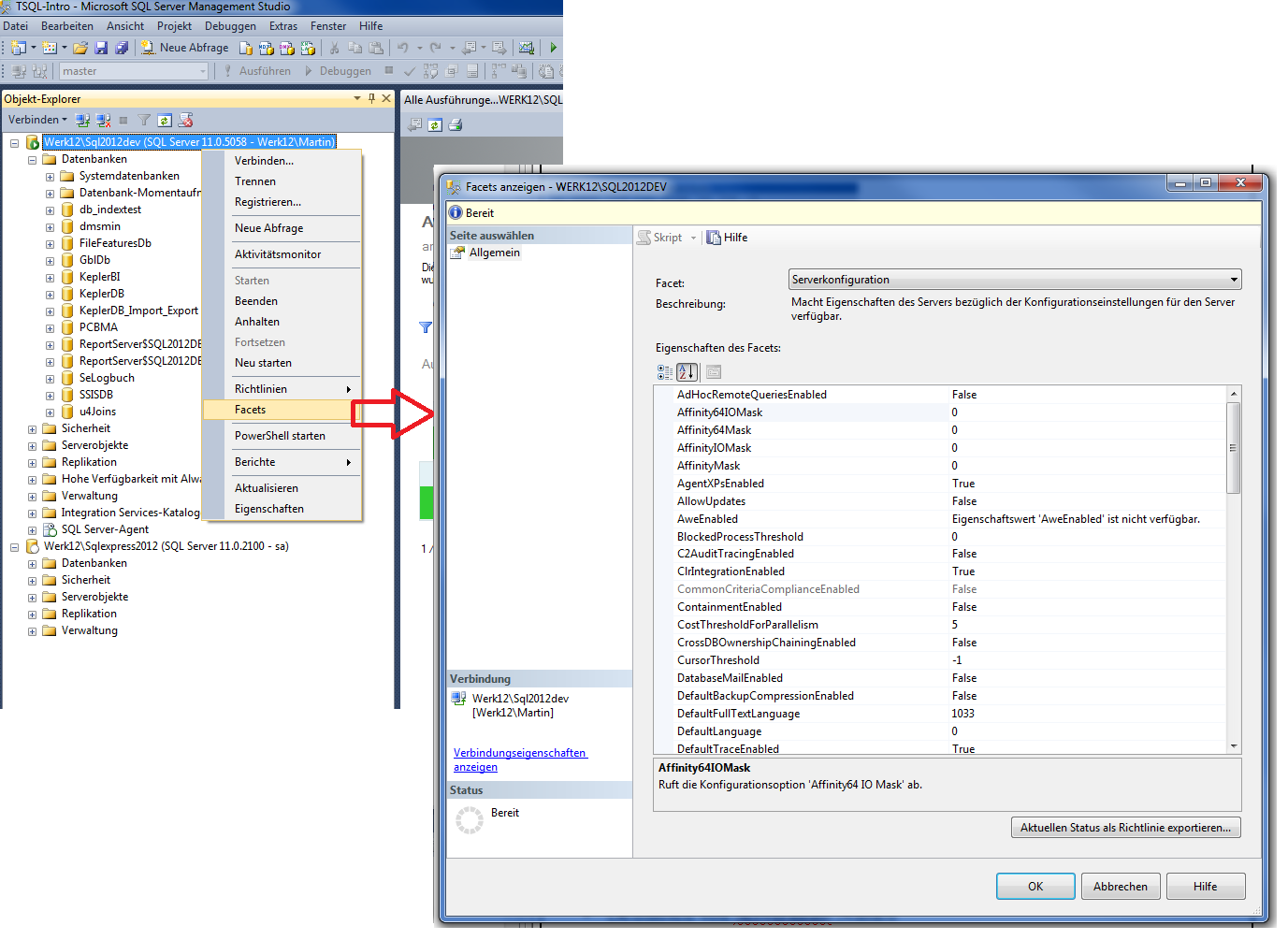
Wird aus dem SQL Server Managment
Studio gestartet. Funktionen des allgemeinen Serversystems werden
hier eingestellt.
2.7.5 SQl Server Informationen
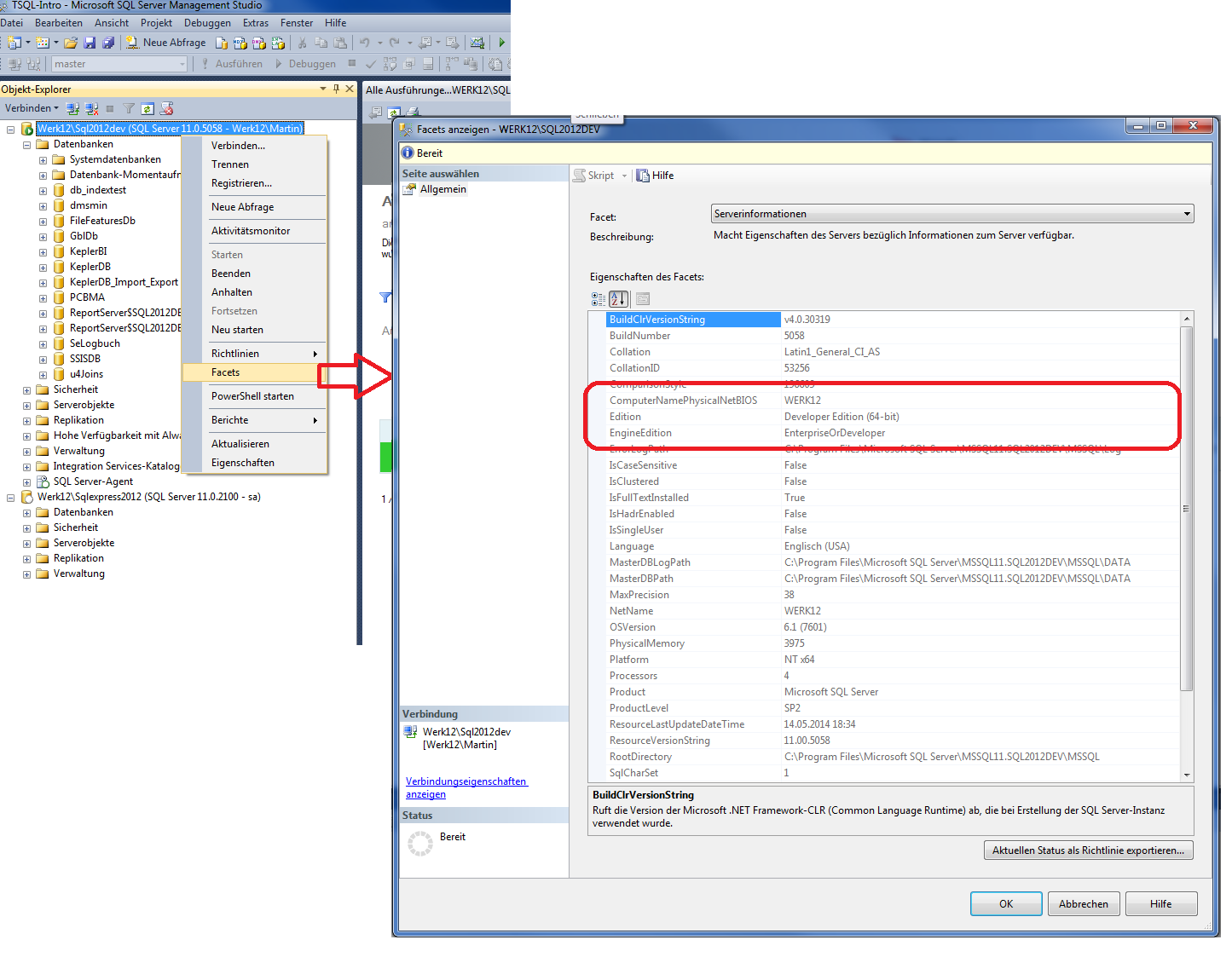
z.B. Bestimmen der Version der
laufenden Instanz.
2.7.6 SQL Server Konfigurationsmanager
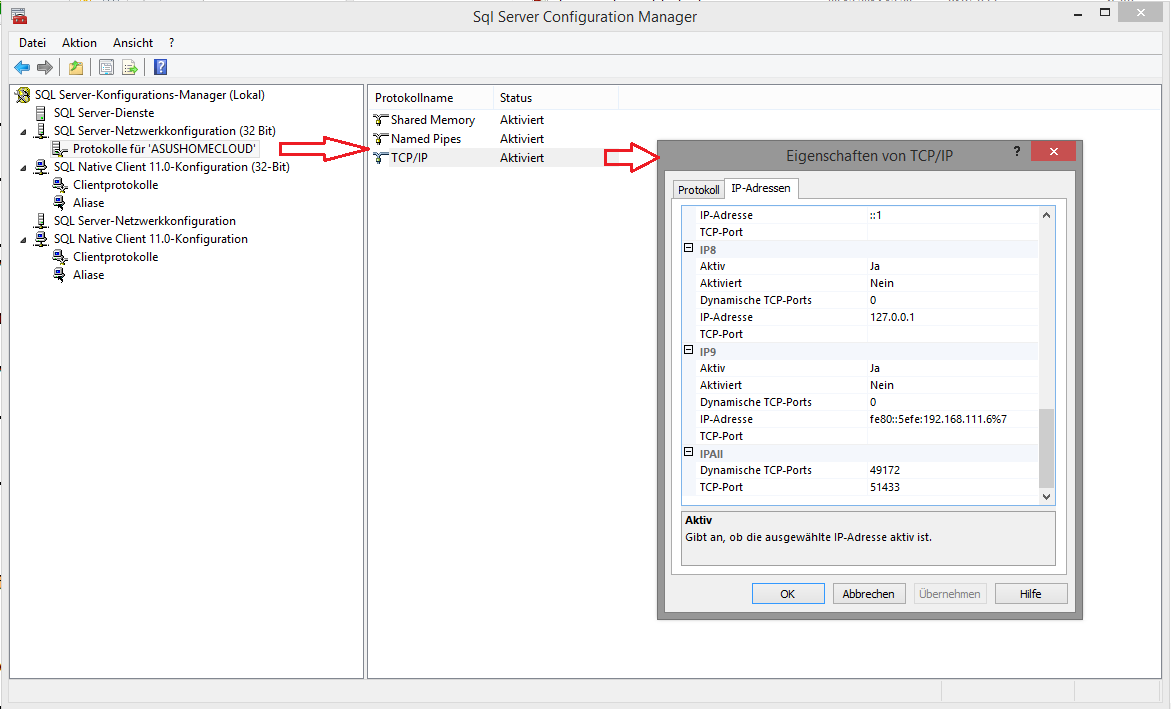
Serverinstanzen starten, stoppen und neu starten
Kommunikationsprotokolle für Server und TCP-
Endpunktekonfigurieren (siehe Screenshot)
Kommunikationsprotokolle der Clients (Managment Studio und
SqlCmd.exe) verwalten
2.8 Administration des Server – und
Datenbankzugriffs
2.8.1 Netzwerkzugriff über TCP- Endpunkte
einschränken
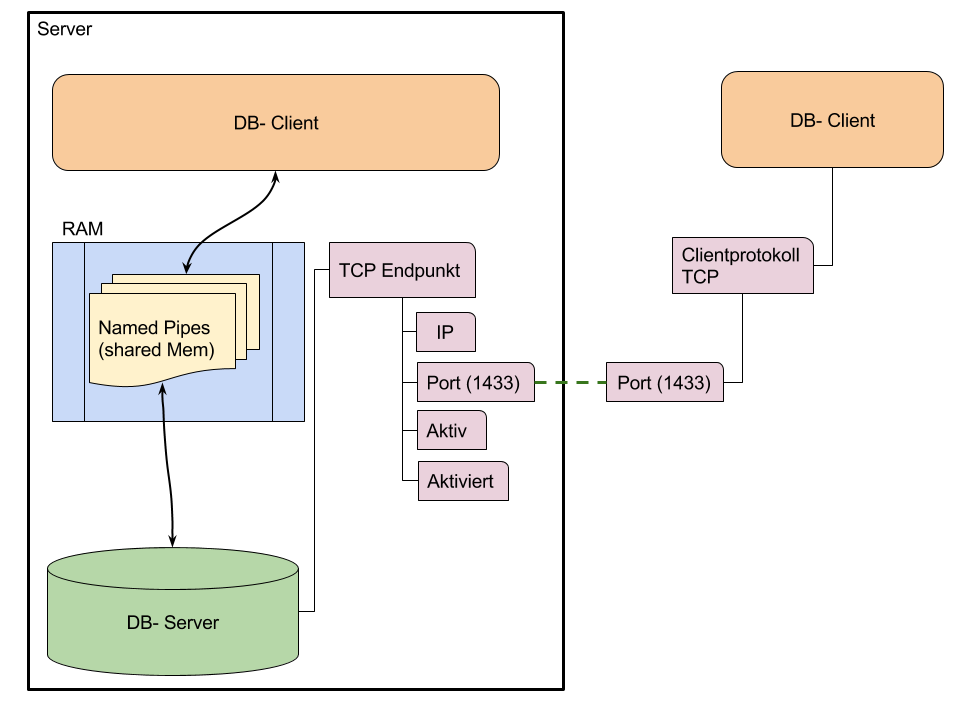
Die erste Barriere, die beim Zugriff auf den SQL- Server über
das Netz zu überwinden ist, ist der TCP- Endpunkt. Seine
Konfiguration erfolgt über den Configuration- Manager in
der Abteilung Server Netzwerkkonfiguration.
TCP- Endpunkte können aktiviert
oder deaktiviert werden. Bezüglich des SQL- Servers wirken sie
ähnlich wie eine Firewall. Indem die Kommunikation mit dem
Server über den Endpunkt eingeschränkt, und bei Bedarf
durch Deaktivierung des Endpunktes gekappt wird, kontrolliert man
sie.
Ein Endpunkt hat die Zustände
started, stopped und disabled. Das Verhalten des
Endpunktes in den jeweiligen Zuständen definiert folgende
Tabelle:
|
started
|
Wartet auf Verbindungsanforderungen, und baut Verbindungen auf.
|
|
stopped
|
Wartet auf Verbindungsanforderungen, lehnt aber Verbindungen
mit einer Fehlermeldung ab.
|
|
disabled
|
Endpunkt ist abgeschaltet, Port nicht aktiv.
|
Im Con figuration- Manager wird
der Zustand eines Endpunktes über die beiden Eigenschaften Aktiv
und Aktiviert eingestellt. Folgende Kreuztabelle stellt die
Zusammenhänge dar:
|
|
Started
|
Stopped
|
Disabled
|
|
Aktiv
|
True
|
False
|
?
|
|
Aktiviert
|
True
|
True
|
False
|
Der Standardport für einen TCP-
Endpunkt ist 1433. In der Firewall des Servers muss eine Regel
für den eingehenden Verkehr definiert werden, die diesen Port
öffnet.
Im Configuration Manager kann
der Port für alle Netzwerkschnittstellen (= IP- Adressen) eine
Servers als TCP- Endpunkte geöffnet werden. Jedoch sollte die
bewusste Aktivierung einzelner Schnittstellen als Endpunkte bevorzugt
werden, da so die Angriffsfläche auf den Server minimiert wird.
Weiter besteht die Möglichkeit
einer dynamischen Port- Vergabe. Um diese zu nutzen, ist im
Configuration Manager unter der Abteilung SQL-Server
Dienste der Sql- Server- B rowser zu aktikvieren.
Die Parameter Aktiv und
Aktiviert (deutsche Version) beeinflussen den
2.8.2 Zugriffsbeschränkung für Benutzer
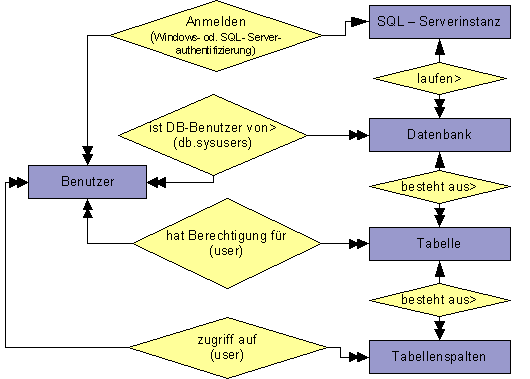
Übersicht
der Zugriffsbeschränkungen eines Benutzers auf Serverressourcen.
2.8.3 Anmeldung am Server
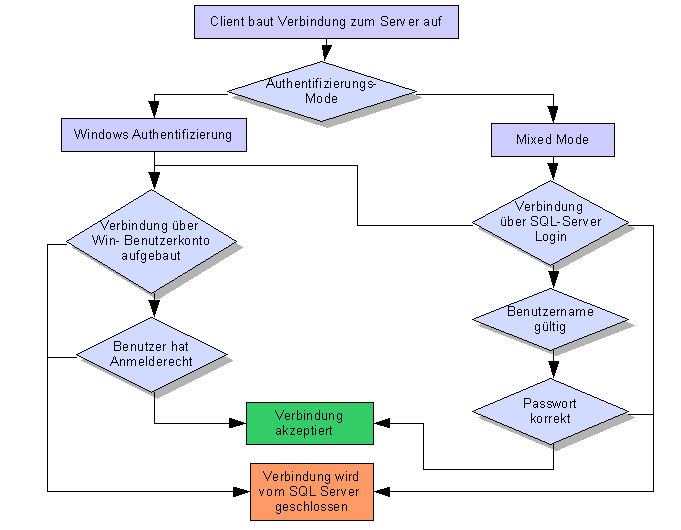
|
Authentifizierungsmodi
|
|
Windows- Authentifizierung
|
SQL- Serverauthentifizierung
|
|
Vorteile:
Mit dem Login am Betriebssystem kann einem Benutzer auch
automatisch Zugriff auf SQL- Server erteilt werden, ohne das
weitere Logins notwendig sind
Übertragung der Passwörter an den Server erolgt
verschlüsselt
Nachteile:
|
Vorteile:
|
Einstellen des Authentifizierungsmodus über SQL Server
Management Studio:
Eigenschaften vom Server\Sicherheit
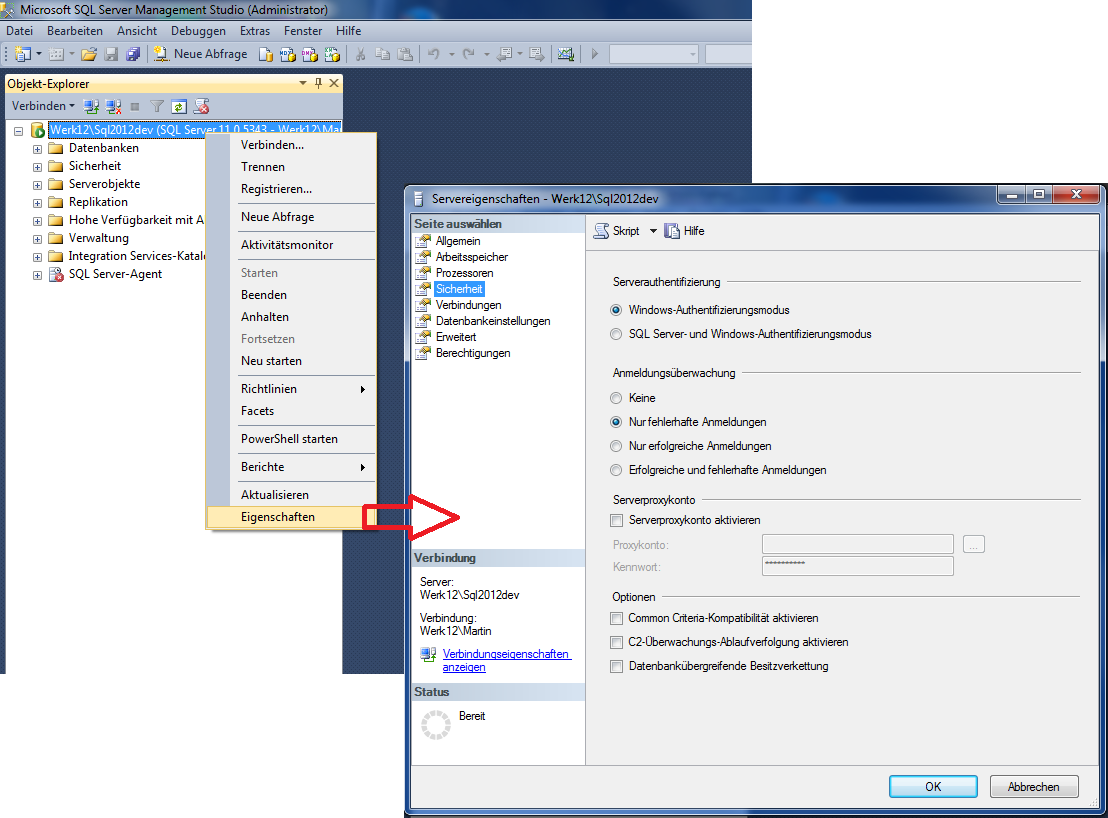
2.8.3.1.1 Auflisten aller Benutzerkonten
exec sp_helplogins
2.8.3.1.2 Auslisten der Windows- Benutzerkonten
select name from sysxlogins where name like '%\%'
2.8.3.1.3 Auflisten aller angemeldeten Benutzer
exec sp_who [ @login_name='login']
2.8.3.2 SQL- Serverauthentifizierung
Für jeden Benutzer wird auf dem Server in der Tabelle
sysxlogins ein Benutzername + Passwort gewspeichert.
use master
go
-- Um die folgende Abfrage auszuführen, muß man Mitglied der Rolle sysadmin sein
select * from sysxlogins
go
2.8.3.2.1 Anlegen eines SQL Benutzerkontos
sp_addlogin [ @loginame = ] 'login'
[ , [ @passwd = ] 'password' ]
[ , [ @defdb = ] 'database' ] -- Datenbank, mit der Benutzer nach der Anmeldung verbunden ist
-- (Standard: master)
[ , [ @deflanguage = ] 'language' ] -- Sprache
2.8.3.2.2 Kennwort ändern
sp_password [ [ @old = ] 'old_password' , ]
{ [ @new =] 'new_password' }
[ , [ @loginame = ] 'login' ]
2.8.3.2.3 Übersicht zu Benutzerkonten erzeugen
sp_helplogins
2.8.3.2.4 Benutzerkonto löschen
sp_droplogin <login>
2.8.3.3 Windows- Authentifizierung
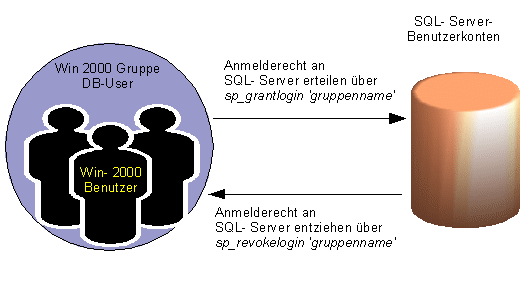
Um
Windows- Benutzerkonten hinzuzufügen, ist ein eigenständiger
Satz von gespeicherten Systemprozeduren vorhanden:
sp_grantlogin [ @loninname = 'loginname']
sp_revokelogin [ @loninname = 'loginname']
sp_denylogin [ @loninname = 'loginname']
2.8.3.3.1 Sicherheitsrichtline für lokale Anmeldung am Server
Um am Server selbst eine Anmeldung als Benutzer durchführen
zu können, ist folgende Einstellung an den lokalen Richtlinen
notwendig
start/programme/verwaltung/lokale Sicherheitsrichtlinien/lokale Richtlinien/
Zuweisen von Benutzerrechten/lokal anmelden-> Gruppe der SQL- Benutzer hinzufügen
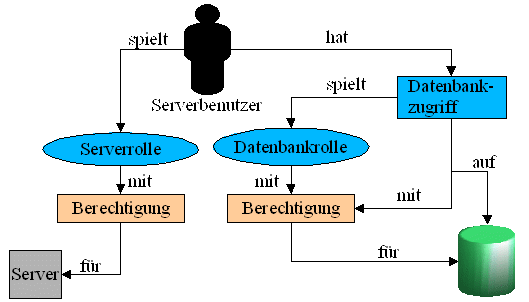
2.9 Zugriff auf Datenbanken
Vorauasetzung für den Zugriff auf eine Datenbank ist
natürlich eine gelungene Authentifizierung (= Anmeldung) am SQL-
Server.
2.9.1 Anmeldungen, Datenbankbenutzer und
Datenbankbesitzer
Damit ein ein angemeldeter Benutzer auf die Objekte einer
Datenbank zugreifen kann, muß er auf einen Datenbankbenutzer
abgebildet werden. So kann unabhängig von den spezifischen
Anmeldekonten eines SqlServers auf einem Windowsserver ein
Zugriffssystem für eine Datenbank entwickelt werden.
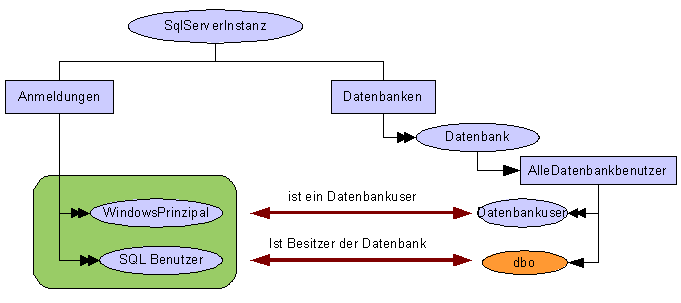
Jede
Datenbank hat genau einen Besitzer. Dieser besitzt implizit alle
Rechte auf eine Datenbank. Dem Besitzer gehört auch das Schema
dbo per Default.
Da es nur einen Besitzer geben kann,
müssen alle weiteren Datenbankbenutzer, die die gleichen Rechte
wie der Besitzer erhalten sollen (nämlich alle), Mitglied der
Rolle db_owner werden.
Die Zusammenfassung einer Menge von
Datenbankbenutzern kann analog den Gruppen in der
Windowsadministration durch sog. Rollen erfolgen. Die
Berechtigungen einer Rolle übertragen sich auf die in der Rolle
enthaltenen Benutzer.
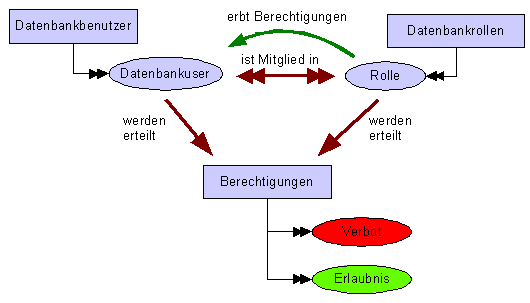
2.9.2 Berechtigungen
Der Zugriff auf den Server und auf Datenbankobjekte kann mittels
Berechtigungen eingeschränkt werden. Die aktuell geltentenden
Berechtigungen stellen einen Sicherheitskontext dar. Dieser kann
durch folgende Aktionen verändert werden:
GRANT: Zugriffsrechte können einem Benutzer
erteilt werden. Entspricht einer Erlaubnis.
REVOKE: Bestehende
Zugriffsrechte werden entzogen
DENY: Zugriffe und
Ausführungsrechte werden explizit entzogen. Entspricht einem
Verbot
Achtung: Verbote
haben Vorrang vor einer Erlaubnis ! Z.B. wird durch ein aus
Mitgliedschaft geerbtes Verbot einer Rolle eine mögliche
individuelle Erlaubnis für einen Datenbankbenutzer eliminiert.
2.9.2.1 Typen von Berechtigungen
|
Anweisungsberchtigungen
|
Objektberechtigungen
|
|
Schränken die Ausführung fogender TSQL- Anweisungen
für einen Datenbankbenutzer ein:
BACKUP DATABASE
BACKUP LOG
CREATE DATABASE
CREATE DEFAULT
CREATE FUNCTION
CREATE PROCEDURE
CREATE RULE
CREATE TABLE
CREATE VIEW
|
Schränken die Ausführung folgender Anweisungen pro
Datenbankobjekt (z.B: Tabelle) für einen
Datenbankbenutzer ein:
SELECT
INSERT
DELETE
EXEC <Stored Procedure>
|
|
Einstellbar in:
Enterprisemanager/<Server>/<Datenbank>/Kontextmenü->
Eigenschaften/ Berechtigungen
|
Einstellbar in:
Enterprisemanager/<Server>/<Datenbank>/Tabellen/Kontextmenü->
Eigenschaften/Berechtigungen
|
2.9.2.2 An wen können Serverberechtigungen erteilt
werden
Windows- Benutzer
Windows- Gruppe
SqlServer Benutzerkonto
2.9.2.3 An wen können Datenbankberechtigungen
erteilt werden
Datenbankbenutzer
Datenbankrolle
2.9.3 Datenbankrollen
2.9.3.1 DBO
DBO ist ein spezieller Datenbankbenutzer. Zum dbo wird man, wenn
man die Datenbank erstellt hat
man mittels sp_changedbowner als Datenbankbesitzer
zugewiesen wurde
Mitglied der Serverrolle Sysadmin
ist (z.B. sa)
Ist man als domaeneX/UserY
angemeldet, und hat die Datenbank DMS erstellt, dann ist
man in DMS auch automatisch der dbo.
Der DBO hat folgende Rechte:
Mitglieder allen Datenbankrollen
außer db_owner hinzufügen
Datenbanken sichern und
wiederherstellen
Prüfpunkte mittels Checkpoint
setzen
Objektberechtigungen in der
Datenbank erteilten
2.9.3.2 db_owner, db_ddladmin
Alle Mitglieder der Rolle db_owner
haben die gleichen Rechte wie dbo. Demgegenüber können die
Mitglieder von db_ddladmin nur DDL- Befehle ausführen.
Objekte, die von Mitgliedern der Gruppe
db_owner und db_ddladmin erstellt werden, haben per Default den Namen
UserName.Objektname.
2.9.3.3 db_accessadmin
Mitglieder dieser Gruppe können
Datenbankbenutzer verwalten
2.9.3.4 db_securityadmin
Mitglieder dieser Gruppe können über Berechtigungen den
Zugriff auf Datenbanken steuern (Sicherheit), indem sie die Befehle
Grant und Revoke ausführen dürfen.
2.9.3.5 db_backupoperator
Mitglieder dieser Gruppe können Datensicherungen auf der
Datenbank durchführen
2.9.3.6 db_datareader
2.9.3.7 db_datawriter
2.9.3.8 db_denydatareader
Mitglieder dieser Gruppe dürfen kein Select auf einer
Datenbank durchführen. So kann ein Datenbankadministrator durch
Mitgliedschaft in db_ddladmin befähigt werden, Tabellen
einzurichten, durch seine Mitgliedschaft in db_denydatareader kann
ihm das Lesen vertraulicher Daten untersagt werden -> Ü
2.9.3.9 db_denydatawriter
Kein Insert, Update, Delete
2.9.4 Datenbankschemas
Ein Datenbankschema ist ein Namensraum für eine
Teilmenge von Datenbankobjekten wie Tabellen, gepeicherten Prozeduren
etc. Jedes Datenbankobjet gehört zu genau einem Datenbankschema.
Neu in SQLServer2005 ist die Trennung zwischen Schema und
Benutzer. In SqlServer 2000 stellte sich die Beziehung zwischen
Schemas und Benzutzer noch wie folgt dar:
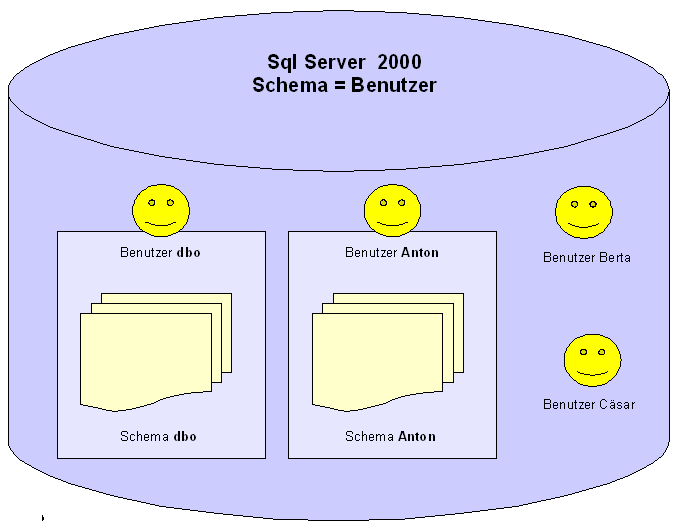
War
im Besitz einer Benutzers ein Schema, dann wurde automatisch mit dem
Löschen des Benutzers das zugeordnete Datenbankschema plus den
darin enthaltenen Objekten wie Tabellen, gespeicherten Prozeduren
etc. gelöscht.
Diese enge Bindung von Benutzern und Schemen wurde in SqlServer
2005 aufgegeben. Schemen können jetzt völlig unabhängig
von Benutzern definiert werden.
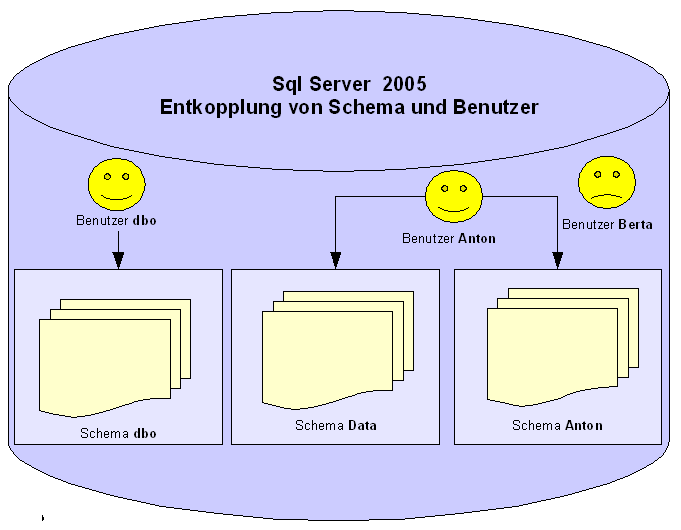
Diese
Entkopplung von Schema und Benutzer hat insbesondere den Vorteil,
dass die Verwaltung der Datenbankobjekte unabhängig von der der
Datenbankbenutzer erfolgt.
2.10 Datenbank anlegen
2.10.1 Grundlagen: Datenbankdateien und
Transaktionsprotokolle
Jede Datenbank besteht aus einer primären und mehreren
sekundären Dateien. Die primäre Datei hat die Endung .mdf.
Die sekundären Dateien haben die Endung .ndf.
Die Speicherorte
der Dateien (Pfade) werden in der master- DB und in der
primären Datei der DB selbst verzeichnet
2.10.1.1 Namensgebung
Datenbankdateien haben einen logischen
und einen physischen Namen. Der logische Name wird in TSQL verwendet.
|
Logischer Name (z.B. FileSysDB)
|
Physischer Name (z.B: c:\db\filesysdb.mdf)
|
2.10.1.2 Aufbau
Der Speicherplatz für eine Datenbankdatei wird blockweise
reserviert. Jeder Block besteht aus 8 Seiten, die jeweils 8 KB Daten
aufnehmen.
Jede Seite nimmt die Daten genau eines Datenbank- oder
Dateiorganisationsobjektes auf. Blöcke, in denen alle Seiten mit
Daten eines einzigen Datenbankobjekt belegt sind, werden als
einheitliche Blöcke bezeichnet. Werden in den Seiten
eines Blockes Daten zu verschiedenen Datenbankobjekten abgespeichert,
dann ist der Block ein gemischter Block.
Das Verzeichnis aller Seiten, die ein
Datenbankobjekt belegt ist ie IAM (Index Allocation Map)
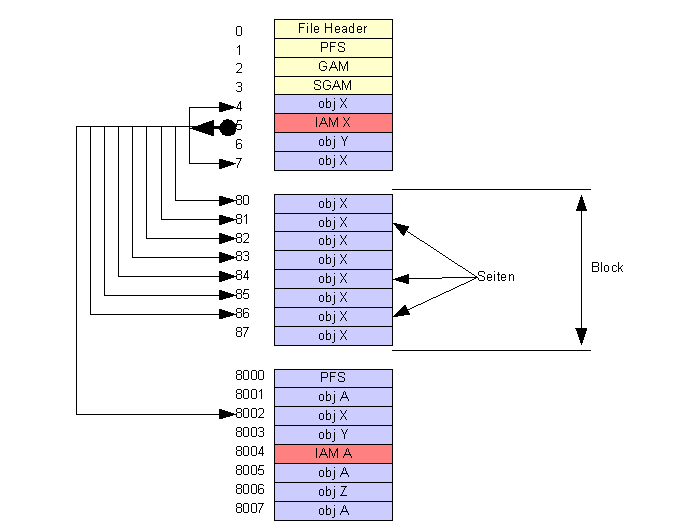
Der erste Block einer Datei enthält den Kopf mit
organisatorischen Infos:
|
Seite
|
Name
|
Inhalt
|
Beschreibung
|
|
0
|
FileHeader
|
DateiID
|
|
|
Anfangsgrösse der Datei
|
|
|
max. Dateigrösse
|
|
|
1
|
PFS
|
Page Free Space
|
Die PFS verzeichnet für jede Seite den Belegungszustand.
Abstufungen: leer, 1-50%, 51-80%, 81-95%, >95%
|
|
2
|
GAM
|
Global Allocation Map
|
Jedes Bit in der GAM kennzeichnet die Belegung eines Blocks in
der Datei. Ist das Bit 0, dann ist der Block noch frei, sonst ist
er belegt. Insgesamt können 64000 Blöcke (= 4
GB)verzeichnet werdn.
|
|
3
|
SGAM
|
Secondary Global Allocation Map
|
Jedes auf 1 gesetzte Bit in der SGAM kennzeichnet einen
gemischten Block, in dem noch midestens eine Seite frei ist.
|
2.10.1.3 Heap
Daten eines Datenbankobjektes, die nicht indiziert sind, werden in
Seiten gespeichert, die dem Datenbankobjekt über die IAM
zugeordnet sind, und in denen noch Speicherplatz vorhanden ist.
Sollte der Speicherplatz nicht mehr ausreichen, dann werden der IAM
neue Seiten zugeteilt. Dies kann die Reservierung neuer Blöcke
nach sich ziehen usw.. Diese ungeordnete Ablage der Daten nach dem
Prinzip "Speichern wo Platz ist" wird Heap genannt.
Der Zugriff auf Daten, die nach dem Heap- Prinzip abgelegt wurden,
ist aufwendig und kann im schlimsten Fall das Durchsuchen der
gesamten Datensammlung zur Folge haben.
2.10.1.4 Indizes
Werden die Datensätze beim Einfügen in die Datensammlung
bezüglich eines Ordnungskriteriums geordnet, dann kann der
Zugriff durch Nutzung der Ordnung stark beschleunigt werden. Das
Ordnen beim Einfügen wird Indizierung genannt.
2.10.1.4.1 Gruppierte Indizes (Clustered Index)
Gruppierte Indizes sorgen für eine physiche Ordnung der
Datensätze, dh. wenn die Daten nach dem < Kriterium geordnet
werden, dann sind die Kleineren Werte auf Seiten mit kleinerer
Seitennummer, und größere Werte auf Seiten mit größerer
Seitennummer zu finden.
Gruppierte Indizes können zur Folge haben, daß beim
Hinzufügen von Daten der Speicherort vorher eingefügter
Datensätze verschoben werden muß. Dies vermindert die
Leistung bei Einfügeoperationen.
2.10.1.4.2 Nicht gruppierte Indizes (Nonclustured Index)
Nicht gruppierte Indizes bewirken keine physiche Ordnung der
Datensätze. Der Index ist ein B- Baum, dessen Blätter auf
die Speicherorte der Datensätze zeigen. Werden die Blätter
des B- Baum von links nach rechts durchlaufen, dann können alle
Datensätze in aufsteigender Folge gemäß dem
Ordnungskriterium besucht werden.
2.10.1.5 Transaktionssystem: Protokolldateien
Alle Datenbankänderungen können in
Transaktionsprotokolldateien mitprotokolliert werden. Dadurch sind
bei einem Systemausfall verloren gegangene Daten wiederherstellbar,
bzw. die Datenbank kann wieder in einen konsitstenten Zustand
überführt werden. Gespeichert werden die
Transaktionsprotokolle in Dateien mit der Endung .ldf.
2.10.1.5.1 Funktionsweise der Protokollierung
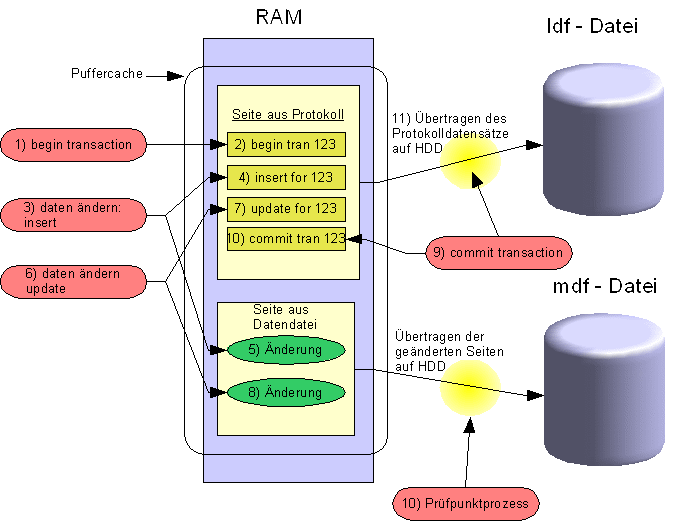
2.10.1.5.2 Prüfpunkt (Checkpoint-) Prozess
Der Prüfpunkt- Prozess sorgt periodisch für die
Sicherung der geänderten Datenseiten im Puffercache auf der mdf-
Datei auf Platte. Nach einem Prüfpunkt sind alle Datenänderungen
auch auf der Festplatte verzeichnet. Sollte das System unmittelbar
nach einem Prüfpunkt ausfallen, dann sind beim Hochfahren des
Servers nur die Anweisungen aller bestätigten Transaktionen aus
dem Protokoll wiederholt auszuführen, die nach dem Prüfpunkt
eröffnet wurden.
2.10.1.5.2.1 Einstellen des Prüfpunktintervalles
use kraftstoff
go
-- Voraussetzungen schaffen, um Prüfpunkte einzustellen (siehe SQL- Server- Hilfe)
exec sp_configure 'show advanced options', 1
reconfigure
go
-- Prüfpunktintervall einstellen
exec sp_configure 'recovery interval', 2
reconfigure
go
Wird 0 Min eingestellt, dann entscheidet der Server selbst, wann
Prüfpunkte gesetzt werden müssen.
2.10.1.5.2.2 Manueller Prüfpunkt
Ein Prüfpunkt kann manuell mit der Anweisung CHECKPOINT
gesetzt werden. Jedoch muss das Script unter einem Konto mit der
Rolle db_owner laufen.
2.10.1.5.3 Verwaltung der Transaktionsprotokolle
Ein Transaktionsprotokoll ist unterteilt in sog. virtuelle
Protokolle.
Jede Folge von Änderungen an der Datenbank wird durch eine
Folge spezieller Datensätze (Logs) in der Protokolldatei
aufgezeichnet. Jeder Datensatz erhält dabei eine LSN (Log
Sequenz Number). Der Beginn der ältesten, noch nicht
abgeschlossenen Transaktion wird durch die MinLSN angezeigt. Die
letzte Änderung, die bereits aus dem Puffercache in die
Datenbank zurückgeschrieben wurde wird durch den letzten
Prüfpunkt angezeigt.
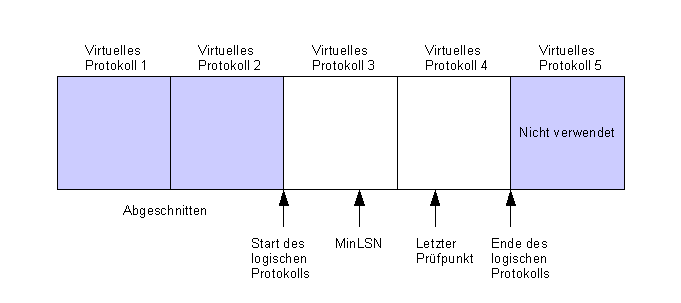
Durch
sichern der Transaktonsprotokolle werden die virtuellen Protokolle
wieder freigegeben, die keine Daten zu aktuell aktiven Transaktionen
beinhalten. Dieser Vorgang wird als Abschneiden bezeichnet. Die
freigegebenen virtuellen Protokolle können dann wieder für
die Aufzeichnung der Logs verwendet werden.
2.10.1.6 Wiederherstellungsmodelle für
Transaktionsprotokolldateien
Die Protokollierung aller Änderungen an einer Datenbank kann
sehr Speicherplatz verbrauchen. Deshalb gibt es die Möglichkeit,
den Umfang der Protokollierung einzuschränken. Dies geschieht
über sog. Wiederherstellungsmodelle. Natürlich geht bei
eingeschränkter Protokollierung Redundanz verloren, wodurch das
Risiko für irreversible Datenverluste steigt.
|
Vollständige
|
Massenprotokolliert
|
Einfach
|
|
|
Indexerstelung und Massenladevorgänge wird nur
eingeschränkt protokolliert- es werden nicht die
Operationen, sondern die durch die Operationen veränderten
Seiten aufgezeichnet
Alle anderen Operationen werden vollständig
aufgezeichnet
Wiederherstellung bis zu einem best. Zeitpunkt in der
Vergangenheit durch eingeschränkte Protokollierung nicht
möglich
Transaktionsprotokolle erfodern beim Wiederherstellen die
Datenbankdateien- fehlen diese, ist eine Wiederherstellung nicht
möglich.
|
Alle Operationen werden vollständig protokolliert
Nach jedem Prüfpunkt werden alle inaktiven Teile des
Protokolles abgeschnitten
Das Modell ermöglicht nur die Wiederherstellung des
Zustandes vor dem Systemausfall bzw. bis zur letzten
Datensicherung
|
Der Wiederherstellungsmodus kann durch folgende TSQL- Anweisung
bestimmt werden:
select DATABASEPROPERTYEX('<datenbankname>', 'recovery')
go
2.10.2 Aufteilen der Daten auf Datenbankdateien
Die Informationen einer Datenbank verteilen sich auf mehrere
Dateien. Die Datenbankinhalte sind in Dateien mit der Extension *.mdf
und *.ndf enthalten. Die Transaktionsprotokolle werden in separaten
Dateien mit der Extension *.ldf gespeichert.
Die Dateien einer Datenbank werden in primäre und
sekundäre Dateien klassifiziert. Jede Datenbank hat eine
primäre Datei mit den Startinfos der Datenbank +
Datenbankobjekten wie Tabellen etc.. Reicht z.B. der Platz auf einer
Fetplattenpartition nicht mehr für die Speicherung aller
Datenbankobjekte aus, dann können mittels sekundärer
Partitionen auf anderen Festplatten zusätzlich Speicherplatz
bereitgestellt werden. Im Enterprisemanager kann in der
Eigenschaftliste einer Datenbank die Zuordnung weiterer sekundärer
Datandateien vorgenommen werden.
Mittels Dateigruppen können
mehrere sekundäre Dateien zusammengefasst werden. Beim Erstellen
einer Tabelle kann ihr als Speicherplatz eine Dateigruppe zugewiesen
werden. Verteilen sich die Dateien einer Dateigruppe auf mehrere
Festplatten, kann so ein Leistungssteigerung ähnlich wie bei
einem RAID5 System erreicht werden.
Wichtig: Daten- und
Transaktionsprotokolldateien von Microsoft® SQL Server™
2000 dürfen nicht auf komprimierten Dateisystemen oder auf einem
Remotenetzlaufwerk, z. B. einem freigegebenen Netzwerkverzeichnis,
erstellt werden.
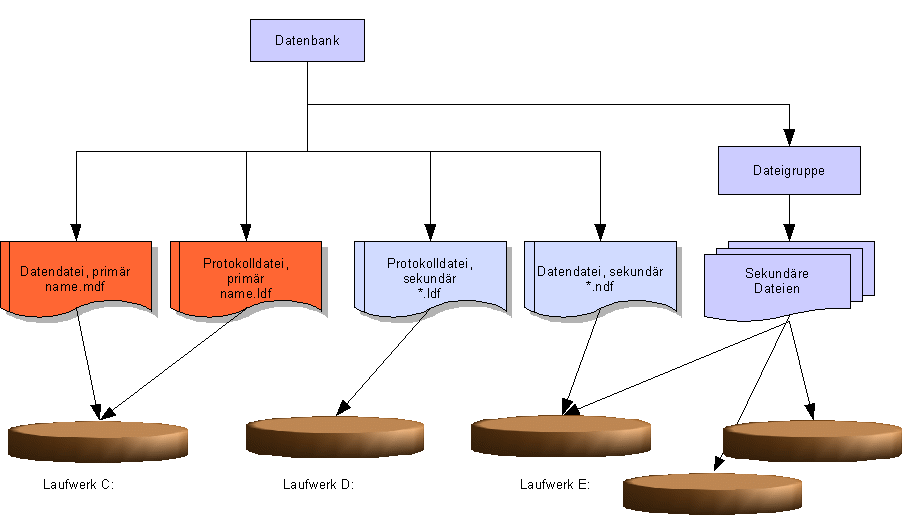
2.10.3 Anlegen mittels TSQL
Datenbanken werden mittels create database angelegt.
Beispiel:
use master
go
if exists(select * from master.dbo.sysdatabases where name ='mko_report')
drop database mko_report
go
create database mko_report
ON
-- Definition der Datendatei
PRIMARY ( NAME = report_dat,
FILENAME = 'c:\sql_mko_report.mdf',
SIZE = 5 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 100 KB )
( NAME = report_dat,
FILENAME = 'e:\sql_mko_report2.mdf',
SIZE = 5 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 100 KB )
-- Definition der Log- Datei
LOG ON
( NAME = Sales_log,
FILENAME = 'c:\sql_mko_report_log.ldf',
SIZE = 5 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 100 KB )
GO
2.10.4 Existierende Datenbankdateien an den Server anbinden und abkoppeln
Um existierende Datenbankdateien an den Server anzubinden, ist
folgende Variante von create Database anzuwenden.
use master
go
create database geoinfo
on (filename = 'c:\mydb\geoinfo.mdf')
log on (filename = 'c:\mydb\geoinfo.ldf')
for attach
Alternativ kann die Datenbank im Enterprisemanager über
Datenbanken\Kontextmenü\Alle Tasks\Datenbank anhängen
wieder angehangen werden.
Datenbanken können vom Server wieder abgekoppelt werden, um
sie z.B. an einen Anwender zu senden. Dies geschieht mittels einer
Prozedur:
use master
go
exec sp_detach 'geoinfo'
go
Alternativ kann die Datenbank im Enterprisemanager über
Datenbanken\<Datenbankname>\Kontextmenü\Alle
Tasks\Trennen abgekoppelt werden.
2.10.5 Datenbankoptionen
Die Datenbankoptionen können eingestellt werden über
Enterprisemanager/<Serverinstanz>/Datenbanken/<Kontextmenü
der Datenbank>/Eigenschaften/Optionen
oder mittels der gespeicherten Prozedur ALTER DATABASE SET
...
2.10.5.1 Wichtige Optionen für Wartungsaufgaben
|
Option
|
Beschreibung
|
|
SINGLE_USER
|
Einzelbenutzermodus Zu jedem Zeitpunkt kann nur ein Benutzer
auf die Datenbank zugereifen
|
|
RESTRICTED_USER
|
Zugriff nur für Mitglieder von db_owner, db_creator oder
sysadmin
|
|
MULTI_USER
|
Keine generelle Zugriffsbeschränkung
|
|
READ_ONLY | READ_WRITE
|
Datenbank ist entwerder Schreibgeschützt (READ_ONLY) und
kann nicht verwendet werden, oder User können auf die
Datenbank lesend und schreibend zugreifen (READ_WRITE)
|
2.10.6 Informationen zu Datenbanken abfragen
Eine Übersicht zu allen eingerichteten Datenbanken auf einer
Serverinstanz kann mit folgender Prozedur gewonnen werden.
exec sp_helpdb
go
Speicherplatzbelegung der Datenbanken explizit abfragen
exec sp_spaceused
go
Speicherplatzbedarf einer Tabelle in einer Datenbank abfragen
use Hypercube
go
exec sp_spaceused 'dbo.FactFiles'
go
2.11 Datensicherung
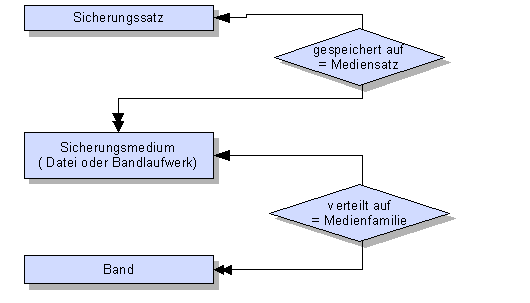
2.11.1 Schritte der Datensicherung
Sicherungsmedium erstellen
Datenbank in den Modus SINGLE_USER umschalten
Datenbankkonsitenz prüfen
Datenbank sichern
2.11.2 Sicherungsmedium erstellen
Ein Sicherungsmedium wird durch einen Eintrag in der
master.sysdevices- Tabelle erstellt. Dabei wird einem Bandlaufwerk
oder einem physischen Dateiname ein logischer Name hinzugefügt,
der später als Beschreibung im BACKUP- Befehl genutzt werden
kann. Die Erstellung erfolgt mit der Systemprozedur sp_addumpdevice:
sp_addumpdevice [@devtype= ] '<device_type>',
[@logicalname = ] '<logical_name>,
[@physicalname= ] '<physical_name>'
|
Parameter
|
Bedeutung
|
|
device_type
|
Gerätetyp. Mögliche Werte:
|
|
logical_name
|
Logischer Gerätename, der in den Sicherungs- und
Wiederherstellungsanweisungen verwendet wird
|
|
physical_name
|
Bezeichnet den Physikalischen Ort des Sicherungsmediums.
Beispiele:
|
Nach erfolgreicher Ausführung des Kommandos befindet sich im
Enterprise- Manager unter Verwaltung/Sicherung ein neuer
Eintrag für das Sicherungsmedium.
Beispiel:
use master
go
exec sp_addumpdevice 'disk',
'geoinfo-disk-bak',
'c:\backup\mko-geoinfo.bak'
go
2.11.3 Aufbau eines Bandmediums
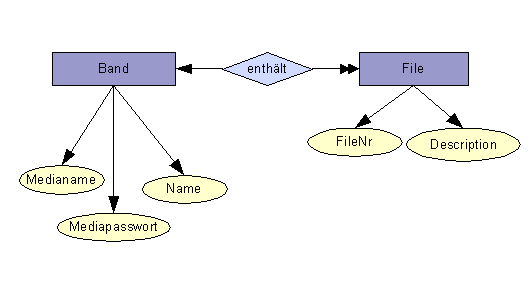
2.11.4 Datenbankkonsitenz prüfen
Die Konststenzprüfung erfolgt mit dem Befehl dbcc checkdb:
dbcc checkdb ('<database_name>' [, NOINDEX | {REPAIR_FAST | REPAIR_REBUILD | REPAIR_ALLOW_DATA_LOSS}] )
[with {[ALL_ERRORMSGS | NO_INFOMSGS]
[, TABLOCK]
[, ESTIMATEONLY]
[, PHYSICAL_ONLY]
[, TABRESULTS]
}
]
Bsp.:
use master
go
-- Wieviel Speicherplatz wird die Prüfung belegen
dbcc checkdb ('geoinfo')with estimateonly
go
-- Prüfung der Datenbank ohne Ausgabe von allg. Infos
dbcc checkdb ('geoinfo') with no_infomsgs
go
-- Reparatur einer Inkonsitenten Datenbank, garantiert ohne Datenverlust.
dbcc checkdb ('geoinfo'), REPAIR_FAST with no_infomsgs
go
-- Die Datenbank kraftstoff wurde zuvor mittels des Tools bomber.pl partiell beschädigt
-- Reparatur mittels dbcc
dbcc checkdb ('kraftstoff', REPAIR_ALLOW_DATA_LOSS)
go
2.11.5 Datenbank sichern
Die Sicherung erfolgt mit dem Befehl backup database:
2.11.5.1 Einfache Sicherung
use master
go
backup database geoinfo
to [geoinfo-disk-bak]
go
2.11.5.2 Sicherung mit Passwort und Angabe der Mindesthaltbarkeit der
Sicherung
backup database geoinfo
to bakfile_geoinfo
go
2.11.5.3 Differentielle Sicherung
Bei der differentiellen Sicherung werden nur die Änderungen
zur vorausgegangenen Vollständigen Sicherung aufgezeichnet.
differentielle Sicherung kann nur angewendet werden, wenn
mindestens eine vollständige Sicherung vorausgegangen ist
differentielle Sicherung ist kumulativ, dh. die dritte
differentielle Sicherung enthält alle Daten der 1. und 2.
differentiellen Sicherung
use master
go
backup database geoinfo to [geoinfo-disk-bak]
go
use geoinfo
go
insert into kennzeichen (kz, land) values ('txt', 'testland')
use master
go
backup database geoinfo to [geoinfo-disk-bak] with differential, noinit
go
2.11.5.4 Sicherung der Protokolle
Die Sicherung der Protokolle setzt voraus, das eine vollständige
Datensicherung stattgefunden hat.
Zwei zusätzliche Optionen zur vorausgeangenen Datensicherung:
|
TRUNCATE_ONLY oder NO_LOG
|
Bewirkt nur ein Abschneiden im Transaktionsprotokoll- keine
Sicherung
|
|
NO_TRUNCATE
|
Sicherungs des Protokolls, auch im Falle, das die Datendatei
verloren gegangen ist.
|
Bsp.: Siehe S. 316
2.11.5.5 Sicherung mit Enterprise- Manager
siehe unter:
<Serverinstanz>/Datenbanken/<Datenbank-Kontextmenü>/Alle
Tasks/Datenbank sichern...
2.12 Wiederherstellung der Datenbank
2.12.1 Automatische Wiederhestellung bei Systemstart
Beim Hochfahren erfolgt eine Automatische Wiederherstellung über
die Transaktionsprotokolle der Datenbanken. Begonnen wird mit der
Masterdatenbank, da die Speicherorte der restlichen Datenbanken in
der Tabelle master.sysdatabases abgelegt ist.
HKEY_LOCAL_MACHINE\Software\Microsoft\MSSQLServer\MSSQLServer\Parameters\
|
+-> master.sysdatabases.files
| |
| +-> Dateipfad von geoinfo
| | |
| | +-> geoinfo.sysfiles
| | +-> geoinfo.sysfilegroups
| |
| +-> Dateipfad von Kraftstoff
| | |
| | +-> Kraftstoff.sysfiles
| | +-> Kraftstoff.sysfilegroups
| |
Der Prozess der automatischen Wiederherstellung ist auch dokumentiert
im Protokoll der Serverinstanz unter:
<server>/Verwaltung/SQL Serverprotokolle
Entscheidend für die Dauer der automatischen Wiederherstellung
ist die Länge des Prüfpunktintervalles.
2.12.2 Manuelle Wiederherstellung
2.12.2.1 Varianten
|
|
|
|
vollständige Wiederherstellung
|
Wiederherstellung aus Sicherung + Transaktionsprotokoll
|
|
Änderungen ab Zeitpunkt X zurücknehmen
|
Wiederherstellung des Zustandes zum Zeitpunkt X
|
|
Wiederherstellen von Transaktionen
|
|
|
Wiederherstellen von Dateigruppen
|
|
2.12.2.2 Voraussetzungen für die Wiederherstellung
Datenbank darf nicht benutzt werden (Kein Benutzer hat
Datenbank mit use geöffnet bzw. auf DB läuft keine
Abfrage)
Nur Bnutzer der Serverrolle
sysadmin, dbcreator oder user dbo dürfen einen Datenbank
wiederherstellen
Transaktonsprotokolle müssen
in der Reihenfolge ihrer Entstehung wiederhergestellt werden
2.12.2.3 Schritte der Wiederherstellung
Den richtigen Sicherungssatz finden
Prüfen, ob der Sicherungssatz verwendbar ist
Wiederherstellung
2.12.2.4 Den richtigen Sicherungssatz finden
Mit folgenden drei Anweisungen können Infos über den
Inhalt von Sicherungsmedien gewonnen werden.
-- Auslesen Kopfinformationen von einem Sicherungsband
restore labelonly form [geoinfo-disk-bak]
-- Auslesen der Informationen zum gesamten Sicherungssatz
restore headeronly from [geoinfo-disk-bak]
-- Auslesen der Liste der gesicherten Datenbank- und Protokolldateien
restore filelistonly from [geoinfo-disk-bak]
2.12.2.5 Prüfen, ob der Sicherungssatz verwendbar ist
Mittels folgenden Befehls kann die Lesbarkeit der Medienfamilie
überprüft werden
restore verifyonly from [geoinfo-disk-bak]
2.12.2.6 Wiederherstellungsoptionen
Sollen einer Wiederherstellung weitere Wiederherstellungen
(differentiell oder aus Transaktionsprotokollen) folgen, dann dürfen
offene Transaktionen durch die aktuelle Wiedeherstellung nicht
zurückgerollt werden (Option Norecovery), um ein nahtloses
aneinandersetzen der Aufzeichnungen zu ermöglichen. Die letzte
Wiederherstellung muß immer mit der Option recovery
abgeschlossen werden, um eine funktionsfähige Datenbank zu
erhalten.
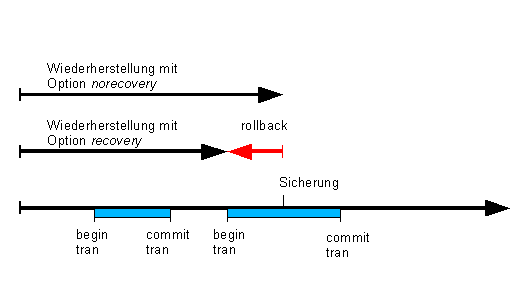
2.12.2.7 Vollständige Wiederherstellung
Die vollständige Wiederherstellung einer Datenbank kann mit
dem Befehl restore database erfolgen:
use master
go
-- Wiederherstellung simpel
restore database geoinfo from [geoinfo-disk-bak]
go
-- Bei der Wiederherstellung werden die Speicherorte der Datenbank- und Protokolldateien verändert
use master
go
restore database kraftstoff from [kraftstoff-disk-bak]
with move 'kraftstoff' to 'c:\db-neu\kraftstoff.mdf',
move 'kraftstoff_log' to 'c:\db-neu\kraftstoff.ndf'
go
-- Überschreiben der laufenden Datenbank durch die Sicherung erzwingen
2.12.2.8 Differenzielle Wiederherstellung
Bei der Differenziellen Wiederherstellung ist wie folgt
vorzugehen:
Vollständige Wiederherstellung mit Option NORECOVERY
(Kein Rollback offener Transaktionen)
Wiederherstellung aus dem Medium mit differenziellen
Sicherungssatz
Diefferenzielle Sicherung sind kumulativ- wurden nach der letzten
vollständigen Sicherung drei Differenzielle angelegt, dann ist
nur die letzte differentielle Sicherung wiederherzustellen.
2.12.2.9 Wiederherstellung von Transaktionsprotokollen
Bei der Wiederherstellung mittels Transaktionsprotokollen ist wie
folgt vorzugehen:
Wiederherstellung der Datenbank mit Option NORECOVERY
Wiederherstellung der Protokolldatei mittels Restore log
use master
go
-- Vollständige Wiederherstellung mit Transportprotokollen
restore database kraftstoff from [kraftstoff-disk-bak] with norecovery
go
restore log kraftstoff from [kraftstoff-log-disk-bak]
go
2.12.2.9.1 Wiederherstellung bis zum Zeitpunkt X
Es wird eine Testdatenbank namens test-restore angelegt:
create database [test-restore]
go
use [test-restore]
go
create table data (
uhrzeit datetime
)
go
Mittels eines folgender Insert- Anweisung, die periodisch aus dem
SQL- Server Agent angestartet wird, werden fortlaufend Datensätze
mit einem Zeitstempel in der Datenbank produziert.
insert into data values(getdate())
go
Als erstes erfolg eine vollständige Sicherung:
backup database [test-restore] to [test-restore-bak]
Zu einem späteren Zeitpunkt erfolgt eine Sicherung des
Transaktionsprotokolles
backup log [test-restore] to [test-restore-bak]
Die Datenbank wird gelöscht, und anschließend mit
folgenden Anweisungen bis zum Zeitpunkt X wiederhergestellt
use master
go
restore database [test-restore] from [test-replikation-bak] with norecovery
go
restore log [test-restore] from [test-replikation-bak] with file=2, stopat='13.11.2003 23:15:00', recovery
go
2.12.2.10 Wiederherstellung mit Enterprise- Manager
siehe unter: siehe unter:
<Serverinstanz>/Datenbanken/<Datenbank-Kontextmenü>/Alle
Tasks/Datenbank wiederherstellen
2.12.2.11 Protokollierung der Wiederherstellungsschritte in
msdb- Tabellen
siehe S. 340
2.13 Fehlermeldungen
2.13.1 Schweregrade
|
Schweregrade
|
Beschreibung
|
|
10
|
Informationsmeldungen
|
|
11- 16
|
Durch Benutzer verursachte Fehler, die durch diesen behoben
werden können
|
|
17, 18
|
Ressourcen und Systemfehler. Die Benutzersitzung wird nicht
unterbrochen
|
|
19-25
|
Schwere Systemfehler
|
2.14 Datenbank Email
In bestimmten Situatioen muß der Server einen Administrator
benachrichtigen über Email, wenn z.B. ein Auftrag des SQL-
Server Agent fehlschlägt, oder der Server an seinen
Leistungsgrenzen stößt. Dazu liefert SQLServer 2005 einen
integrierten Email- Client, genannt Databank Email.
Wichtig: Dieses Feature muß
zuerst in der Oberflächenkonfiguration freigeschaltet werden.
Konfiguriert wird
der Client mittels eines Assistenten. Es entsteht dabei ein
Verbindungsprofil.
Eine Email kann
nach erfolgreicher Konfiguration mittels einer gespeicherten Prozedur
wie folgt gesendet werden:
use
master
go
EXEC msdb.dbo.sp_send_dbmail
@profile_name = 'mkomailprofil',
@recipients = 'Martin.Korneffel@t-online.de',
@body = 'The stored procedure finished successfully.',
@subject = 'Automated Success Message' ;
2.15 Automatisieren mit dem SQL Server Agent
Der SQL Server Agent ermöglicht die eine automatisierte
Überwachung und Wartung einer Serverinstanz.
Analog dem Windows- Taskplaner können Datensicherungen und
das Einspielen neuer Daten mittels DTS automatisiert werden. SQL
Server Agent ermöglicht:
Das Auftragsmodul startet Jobs wie Datensicherungen
oder das Einspielen neuer Daten mittels DTS zu bestimmten
Zeitpunkten oder dynamisch auf Anforderung
Das Warnmodul generiert
versendet Emails oder Net Send- Nachrichten, wenn ein Ereignis (z.B.
Fehler beim Einfügen in Datenbank), ein Leistungsindikator
einen Wert überschreitet oder ein benutzerdefinierter Fehler
mittels RAISERROR(...) WITH LOG generiert wurde
Definieren Operatoren, die durch
Warnungen oder über den Forschritt von Jobs benachrichtigt
werden sollen.
Achtung: Sollen Operatoren
mittels net send <ip> <nachricht> benachrichtigt
werden, dann muß der Nachrichtendienst von Windows gestartet
sein.
Für die
Implementierung des SQL Server Agent dient die Systemdatenbank msdb.
2.15.1 Jobs
Eine Übersicht zu allen Jobs kann
mit folgender gespeicherter Prozedur gewonnen werden:
exec msdb.dbo.sp_help_job
Jobs, die im SQL- Server- Agent definiert wurden, können mit
folgenden gespeicherten Prozeduren aus der Datenbank msdb
gestartet und gestoppt werden:
exec msdb.dbo.sp_start_job '<jobname>' -- Startet eine Job auf dem Server
exec msdb.dbo.sp_stop_job '<jobname>' -- Stoppt einen Job auf dem Server
2.15.2 Warnungen
2.15.3 Operatoren
2.15.4 Aufgaben
Erstellen Sie einen Auftrag, der
im Minutentakt das Script DMSsimpelUpdateDB.pl startet, welches die
Datenbank DMS aktualisert
Erstellen Sie eine Warnung, die
beim Überschreiten von X- MB in den Dateigrößen die
eine Warnung via Net Send sendet
2.16 Daten importieren und exportieren
Mit Integration Services biete
der SQL- Server Codegeneratoren zum erstellen von Datenimport- und
Exportprozeduren an. Die Codegeneratoren können über
Assistenten konfiguriert werden, die im SQL- Server Management Studio
gestartet werden:
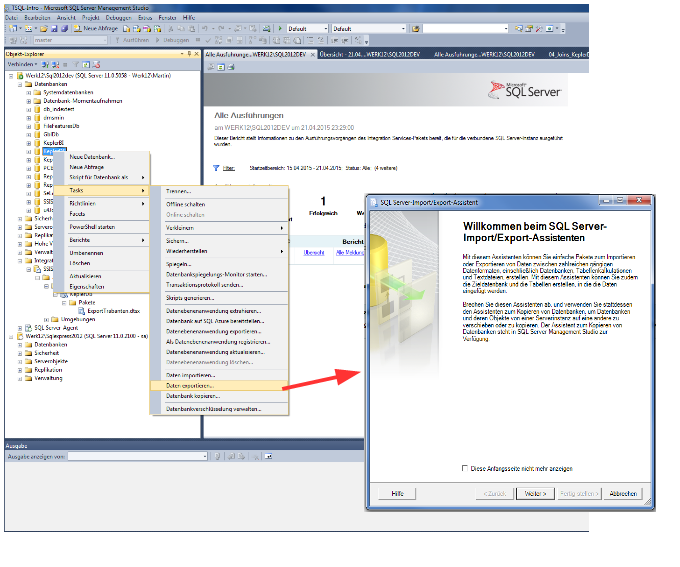
Import-
Export Routinen werden als Pakete bezeichnet und realisieren im
wesentlichen folgende Datenflussgrafen:
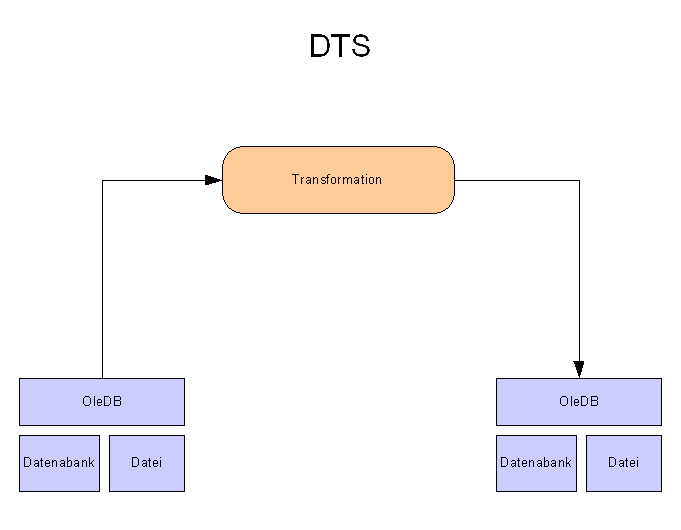
Die
erstellten Pakete können im Integration Service Katalog
abgelegt werden, der sich auf
der Instanz befindet. Einrichtung von Kataloge siehe
https://msdn.microsoft.com/de-de/library/gg471509.aspx.
Über ihre Kontextmenü sind
die Pakete konfigurierbar (z.B. Name der csv- Datei, in die
Exportiert werden soll, ist einstellbar).
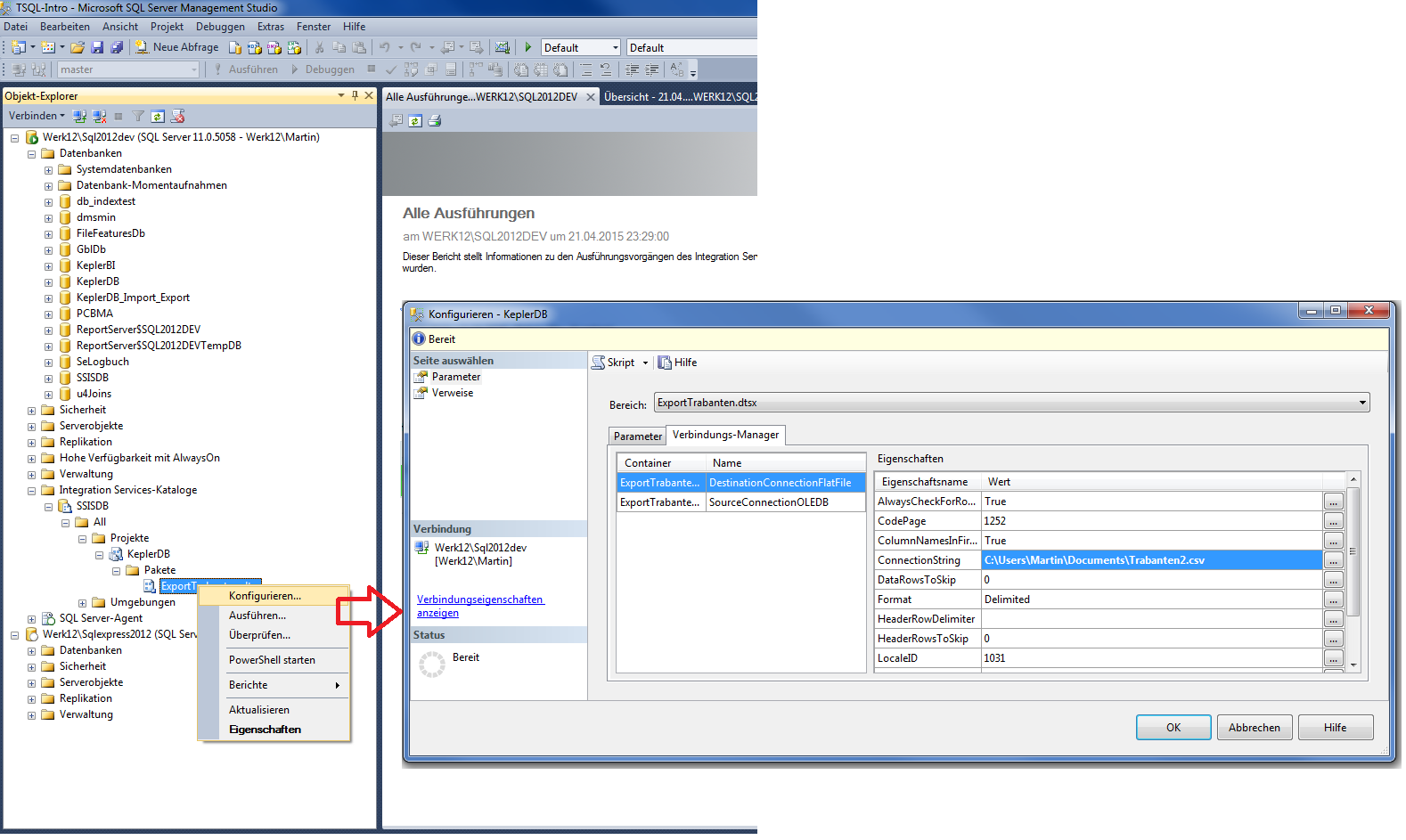
2.17 Verteilte Abfragen und Transaktionen
SQL- Server ermöglicht, Datenquellen, die über mehrere
Instanzen verteilt sind, aus einer Query abzufragen. Dazu sind für
alle Instanzen, die die Daten bereitstellen, als sog.
Verbindungsserver in der Instanz einzurichten, von der aus die
Abfrage ausgeführt wird
(Enterprisemanager/Instanz/Sicherheit/Verbindungsserver).
In den Abfragen, die auf die verteilten
Datenquellen zugreifen, sind diese wie folgt zu spezifizieren:
<SERVERNAME>[\<INSTANZNAME>].<datenbank>.<user>.<objekt>
Beispielsweise kann die Tabelle KONTEN der Datenbank BANK auf
dem Server FILIALE1 wie folgt von einem entfernten Server
abgefragt werden:
select * from FILIALE1.BANK.dbo.KONTEN
go
2.17.1 Verteilte Transaktionen
Implementiert werden die verteilten Transaktionen vom Distributet
Tansaction Coordinator (MS DTC). Dieser ist Bestandteil von
Win2000 und kann über
Start/programme/Verwaltung/Komponentendienste/Computer/Arbeitsplatz
administiert werden.
SET
XACT_ABORT ON
Gibt an, ob Microsoft SQL Server für die aktuelle
Transaktion automatisch ein Rollback ausführt, wenn eine
Transact-SQL-Anweisung einen Laufzeitfehler auslöst
2.17.1.1 TSQL
Sollen eine Reihe von verteilten TSQL- Anweisungen als Transaktion
ausgeführt werden, dann muß anstelle des einfachen BEGINN
TRANSACTION die erweiterte Variante BEGIN DISTRIBUTED
TRANSACTION verwendet werden.
Im folgenden Beispiel versucht sich der
Mitarbeiter Donald mittels einer verteilten Transaktion alle Jobs,
bei denen Geld gezählt wird, anzunehmen:
BEGIN DISTRIBUTED TRANSACTION
update FILIALE1.JOBBOERSE.dbo.JOBS
set status='angenommen', bearbeiter='Donald'
where job='Geld zählen' and status='angebot'
go
update FILIALE2.JOBBOERSE.dbo.JOBS
set status='angenommen', bearbeiter='Donald'
where job='Geld zählen' and status='angebot'
go
COMMIT TRANSACTION
2.18 Replikation
Durch Replikation werden an verschiedenen Standorten aktuelle
Kopien von OLTP- Datenbanken verteilt bzw. eine einheitliche
Datenbasis geschaffen.
2.18.1 Replikationsarten
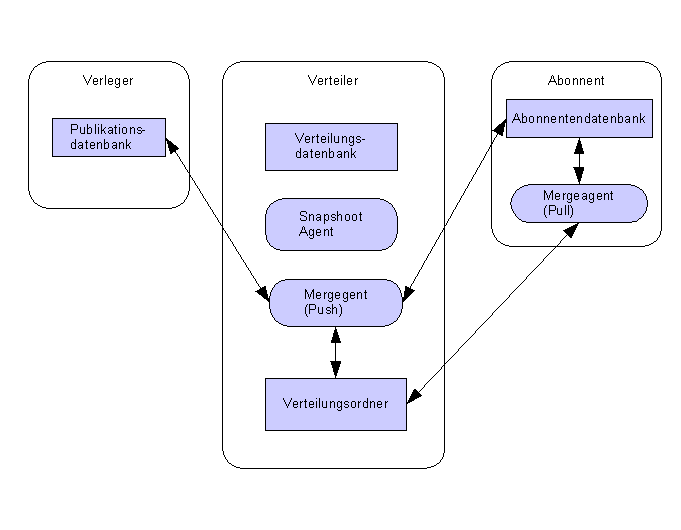
2.18.1.1 Mergereplikation
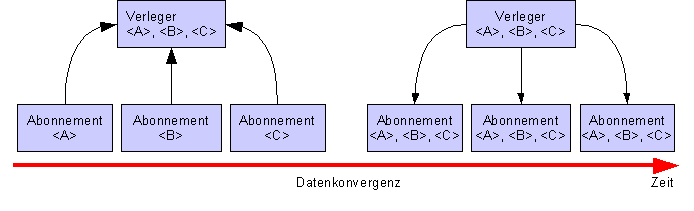
Bsp:
Blackboard
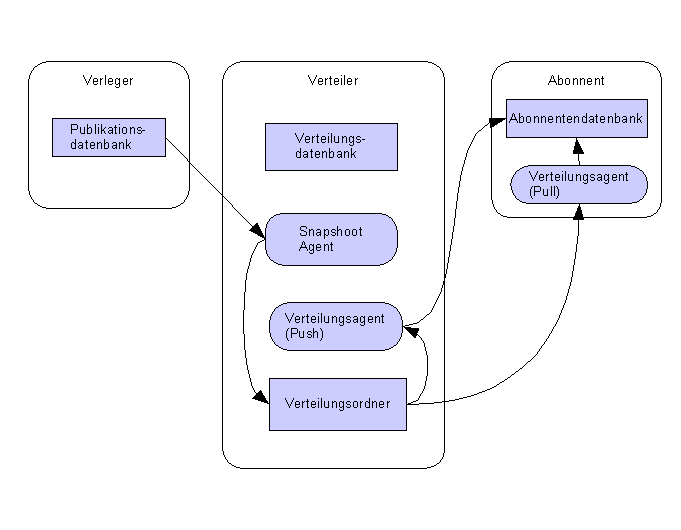
2.18.1.2 Snapshotreplikation/Transaktionsreplikation
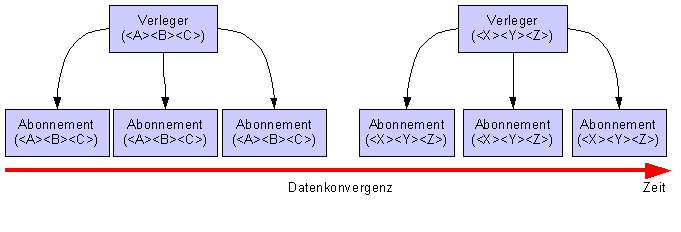
Die
Snapshootreplikation Erzeugt in größeren Intervallen
komplette Kopieen einer von Artikeln auf dem Verleger. Hingegen
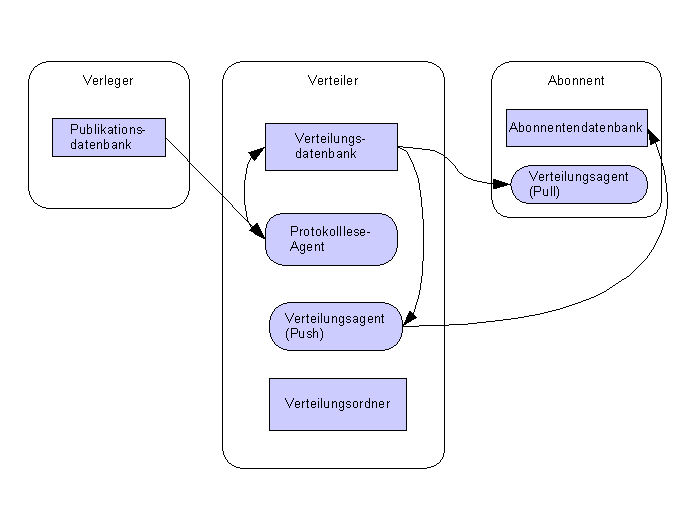
werden bei der Transaktionsreplikation kontinuierlich die Änderungen
vom Verleger an den Abonnenten übertragen.
Bsp: Zeitung, DMSsimpel
2.18.2 Replikationssystem
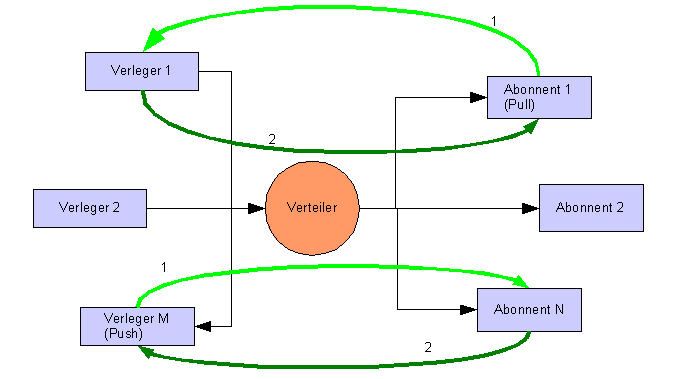
2.18.2.1 Pullabos
2.18.2.2 Pushabos
Können zusammen mit der Publikation auf dem Verleger
erstellt werden
zentraliserte Aboverwaltung beim Verleger
höhere aktualität bei den Abonnenten, da Verteilung
unmittelbar nach Änderung vom Verleger aus angestossen werden
kann
höhere Sicherheit, da Verleger bestimmt, wer was
abonniert
2.18.2.3 Einschränkungen
Tabellen müssen einen Primärschlüssel haben
(außer bei Snapshot)
master, model, msdb, tempdb können nicht repliziert
werden
Jede Publikation kann nur Artikel aus einer DB enthalten
2.18.3 Implementation der Replikationsarten
2.18.3.1 Snapshotreplikation
2.18.3.2 Transaktionsreplikation
2.18.3.3 Mergereplikation
2.18.4 Implementation der Replikation
Verteilungsserver installieren
Publikation erstellen
Abos erstellen
2.18.4.1 Voraussetzungen
Jeder an der Replikation teilhabende Server muß im
Enterprise- Manager registriert sein
Domänen- Konto einrichten, welches alle SQL- Server
Agents gemeinsam nutzen. Das Konto muß auf dem
Verteilungsserver zur lokalen Gruppe der Administratoren (W2000) und
der Sysadmins (SQL 2000) gehören
2.18.4.2 Verteilungsserver installieren
Die Installation des Verteilers erfolgt über einen
Assistenten unter Extras/Replikation/Publizierung, Abonnenten und
Verteilung Konfigurieren im Enterprisemanager.
2.18.4.3 Publikation einrichten
Enterprise Mgr/Extras/Replikationen/Publikationen erstellen und
verwalten
2.18.4.4 Pullabo einrichten
Achtung: Abonnentensicherheit/Identität des SQL-
Server Agent Konto auf Aboserver annehmen (Vertraute Verbindung)
Achtung: Der Zeitplan des Snapshootagenten sieht per
default einen Periodenlänge von einer Woche vor. Bei
Snapshootreplikation hier kürzen auf die gewünschte
Periodenlänge
Achtung: Der Zeitplan für ein Push- Abo bei der
Mergereplikation sieht eine Periodenlänge von einer Woche vor.
Hier kürzen auf die gewünschte Periodenlänge. Der
Zeitplan Fortlaufend ist nichtdeterministisch und deshalb für
Experimente weniger geeignet.
2.19 Überwachung des Servers
2.19.1 Version der Serverinstanz bestimmen
select @@version
2.19.2 Auflisten aller angemeldeter Benutzer
exec sp_who
go
2.19.3 Auslastungsgrad und Laufzeit von Abfragen bestimmen
exec sp_monitor
go
select * from words order by file_id, pos
exec sp_monitor
go
2.19.4 Konfiguration von Warnungen und Leistungsprotokollen
2.19.5 Leistungsindikatoren von SQL- Server
|
Objekt
|
Indikator
|
Beschreibung
|
|
SQLServer:Buffer Manager
|
cache hit ratio
|
Gibt an, wie häufig Datenbankobjekte im Speicher
vorgefunden werden. Wert sollte zw. 90% - und 100% liegen
|
|
|
Database Pages
|
Anzahl der Seiten, die von der Datenbank verwendet werden
|
|
Process
|
Processortime für sqlServer
|
CPU- Auslastung durch den SQL- Serverprozess
|
|
SQLServer:Database
|
LogFlushes/s
|
Anzahl der Protokolldatensätze, die pro Sekunde auf die
HDD, widerspeigelt das aktuelle Arbeitsaufkommen
|
|
SQLServer:Database
|
Transactions/s
|
Anzahl der aktiven Transaktionen pro Sekunde
|
2.20 Quellen
Technische Infos zum SQL-
Server
Probleme
+ Lösungen
SQLXML- HowTo